0x00 前言
作为一个安全从业人员,在平常的工作中总是需要对一些web系统做一些安全扫描和漏洞检测从而确保在系统上线前尽可能多的解决了已知的安全问题,更好地保护我们的系统免受外部的入侵和攻击。而传统的web安全检测和扫描大多基于web扫描器,而实际上其是利用爬虫对目标系统进行资源遍历并配合检测代码来进行,这样可以极大的减少人工检测的工作量,但是随之而来也会导致过多的误报和漏报,原因之一就是爬虫无法获取到一些隐藏很深的系统资源(比如:URL)进行检测。在这篇文章里,笔者主要想和大家分享一下从另一个角度来设计web扫描器从而来解决开头所提到的问题。
0x01 设计
在开始探讨设计之前,我们首先了解一下web漏洞检测和扫描的一般过程和原理。通常我们所说的web漏洞检测和扫描大致分为2种方式:
- web扫描器:主要利用扫描器的爬虫获取目标系统的所有URL,再尝试模拟访问这些URL获取更多的URL,如此循环,直到所有已知的URL被获取到,或者利用已知字典对目标系统的URL进行暴力穷举从而获取有效的URL资源;之后对获取的URL去重整理,利用已知漏洞的检测代码对这些URL进行检测来判断目标系统是否存在漏洞
- 人工检测:通过设置代理(如:burp)来截获所有目标系统的访问请求,然后依据经验对可能存在问题的请求修改参数或者添加检测代码并重放(如:burp中的repeat功能)从而判断目标系统是否存在漏洞
对比上面的2种方式,我们可以发现web扫描器可以极大的减少人工检测的工作量,但是却因为爬虫的局限性导致很多事实上存在的资源不能被发现容易造成就误报和漏报;而人工检测可以很好的保证发现漏洞的准确性和针对性,但是却严重依赖于检测人员的经验和时间,尤其是大型系统很难在有限的时间内完成检测,同样会造成漏报。那么,如果能有效地利用扫描器的处理速度以及人工的精准度的话,是不是就可以很好地解决前面的问题了呢?
下面让我们来深究一下两者的各自优势,前者自动化程度高不需要过多的人为干预,后者因为所有请求均来自于真实的访问准确度高。我们不禁思考一下,如果我们有办法可以获取到所有的真实请求(包括:请求头,cookie,url,请求参数等等)并配合扫描器的检测代码是不是更加有针对性且有效地对系统进行漏洞检测呢?
我们设想一下,如果有这样一个系统可以在用户与系统之前获取到所有的请求,并分发给扫描器进行检测,这样只要请求是来自于真实的应用场景或者系统的功能那么就可以最大程度地收集到所有真实有效的资源。故可以设计该系统包含如下的子模块:
- 客户端:用户访问系统的载体,如:浏览器,手机APP
- 代理:用于获取来自于客户端的所有请求,如:Burp,Load Balancer
- 解析器:负责将代理获取的请求数据按照规定格式解析并插入至请求数据库中
- 请求数据库:用于存放代理获取的所有请求数据以及解析器和扫描器的配置信息
- 扫描器:具有漏洞检测功能的扫描器,如:自行编写的定制扫描器(hackUtils),SQLMAP,Burp Scanner,WVS,OWASP ZAP等
- 应用系统:目标应用系统,如: Web系统,APP
基本架构如下:
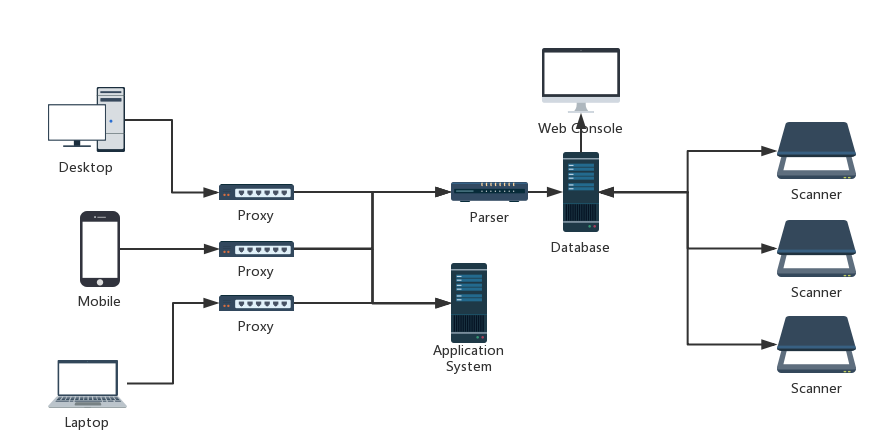
从上图的设计中,我们可以利用代理将所有访问目标系统的请求获取并存储在一个统一的数据库中,然后将这些真实产生的请求分发给不同的扫描器(比如:常见的OWASP Top10的漏洞,已披露的常见框架或者中间件漏洞等)进行检测。上述设计是高度解耦合地并且每个子模块都是只负责自己的功能相互之间并不干扰,且仅通过中心数据库关联起来,因此我们可以通过设置多个代理和扫描器地随意组合来实现分布式地批量检测。
这种设计架构可以很方便地进行扩展和应用, 例如:
- 对于漏洞检测或者安全测试人员,我们只需要在本地设置好代理(如:burp),然后在浏览器或者移动APP中正常地访问或者测试应用的每一个页面和功能,接下来的漏洞检测工作就完全交给了扫描器去做,这将极大地节约了时间和避免了大量重复的手工检测的工作量
- 对于企业系统,我们可以将代理设置在应用前端(如:load balancer),这样所有的请求将会被自动镜像在扫描数据库,并自动分发给多个扫描引擎进行检测,无需手工干预即可发现很多隐藏很深的漏洞
0x02 实践
俗语说的好,“Talk is cheap, show me the code”! 是的,为了更好地了解这种设计思路的好处,笔者设计了一个Demo系统。该系统利用了burp作为代理,当我们在浏览器或者手机的wifi中配置好了代理服务器,漏洞检测的工作将会简化成简单地浏览应用的每一个页面和功能,代理将会自动地收集产生的所有请求数据(包括,各种请求头,cookie,请求方法,请求数据等)然后通过解析器的解析并存储于中央数据库,然后再分发于多个扫描引擎对请求的所有可控输入点进行repeat检测。
效果如下:
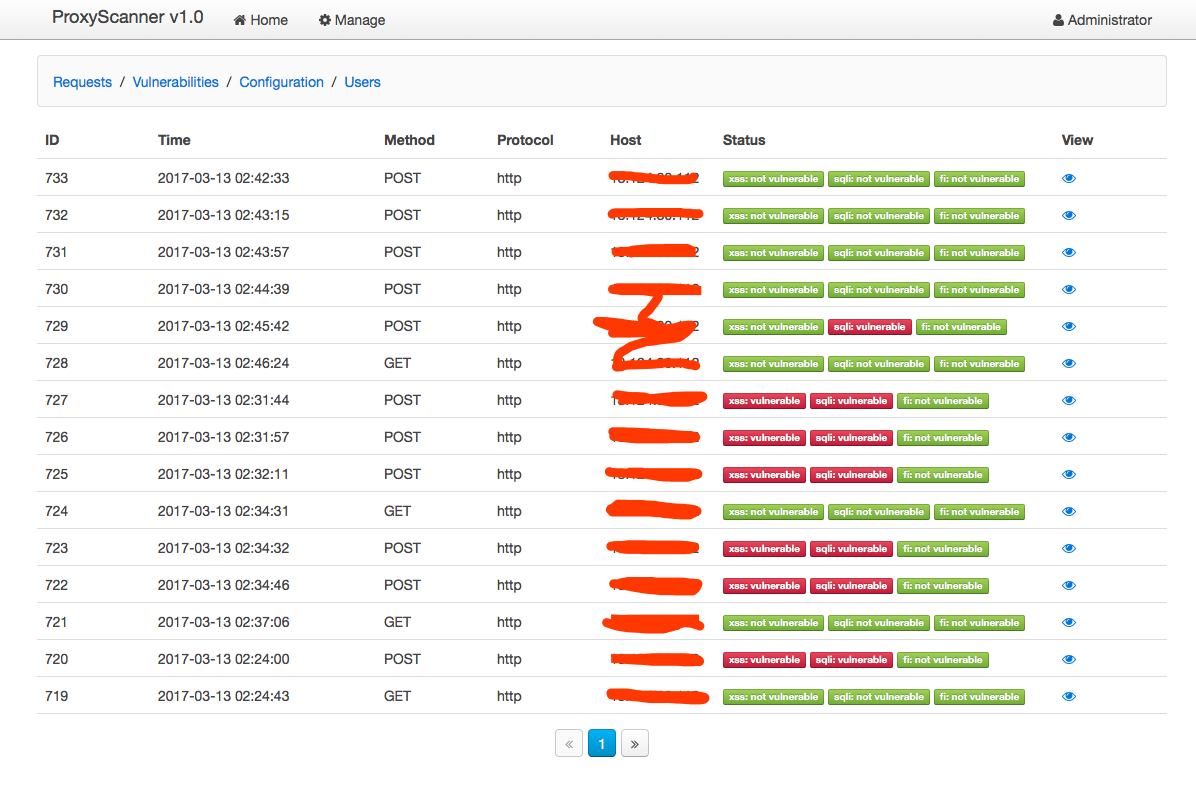
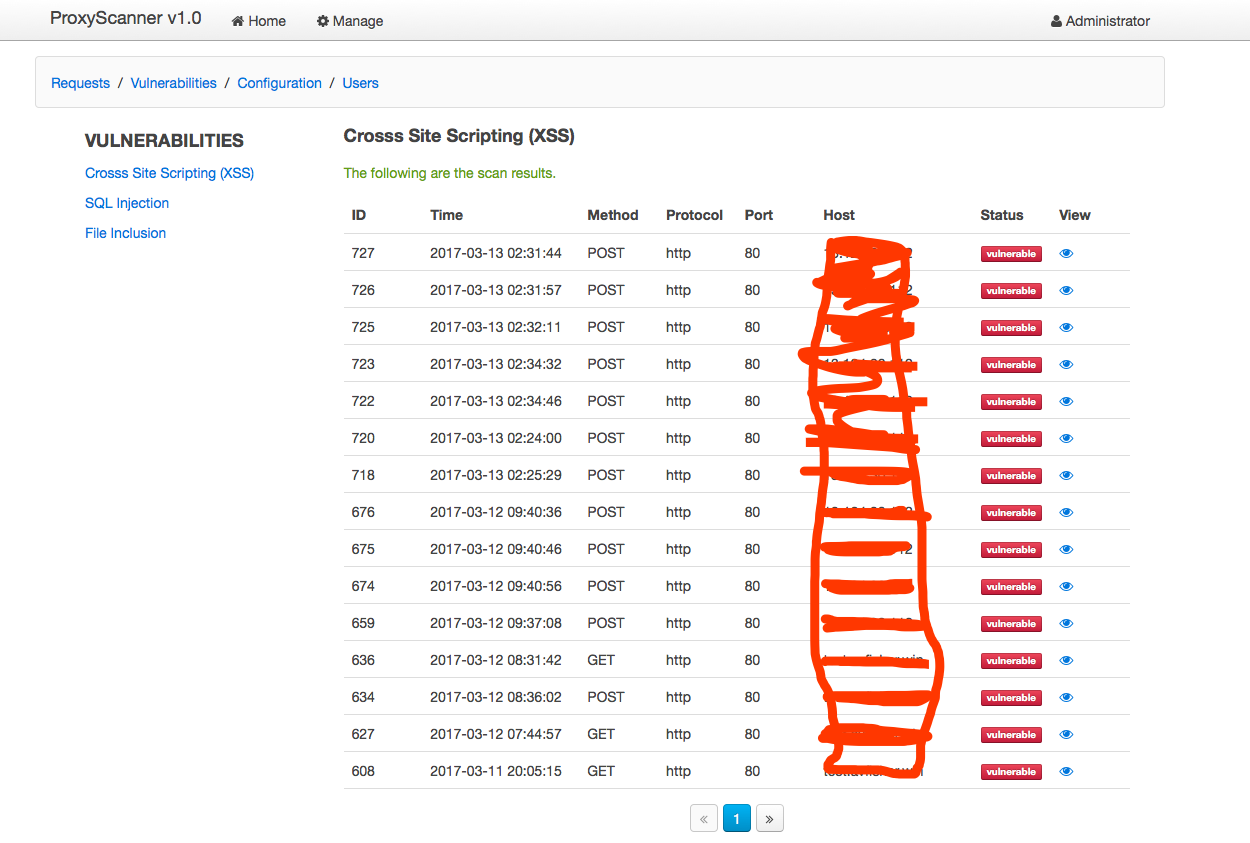
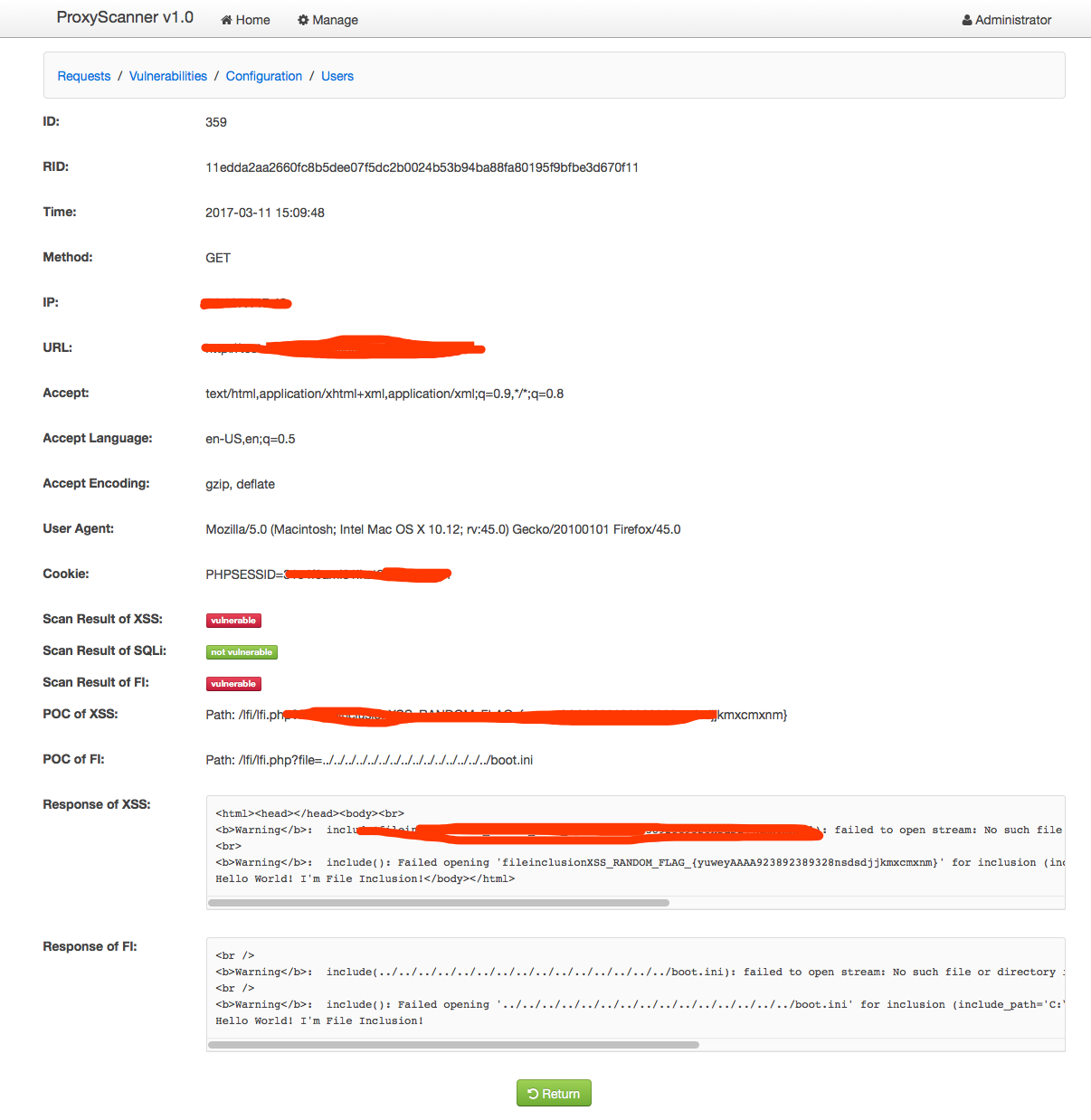
以下是我封装的一个python的requests库,它支持发送自定义的cookie,headers的get/post的请求,并可以是使用PhantomJS引擎去解析和渲染GET请求响应的页面中的javascript,css等,可以非常方便的应用于反爬虫和DOM型XSS的检测。
Code:https://github.com/brianwrf/HackRequests
0x03 思考
从漏洞检测的角度来说,经过笔者的测试(以DVWA和WebGoat为例)检测效果还是非常明显和有效的。其实这种类似的设计,很早之前就已经有人做了,那么很多人要问了为什么你还要在重复造个轮子呢?其实原因有以下几点:
- 系统耦合性较强,不利于进行扩展和改造
- 在HTTPS的流量捕获上支持的不是很好
- 没有做到对HTTP请求中所有的可控输入点进行检测,例如,仅仅检测GET/POST数据,而对cookie,user-agent, referer等缺乏检测
- 缺乏对于DOM的渲染和解析,容易造成对于基于DOM的漏洞的漏报,比如:DOM型的XSS等
- 不具备分布式部署的能力,无法有效利用分布式处理的优点来提高检测效率
- 不具备真正的意义上的repeat检测能力,换句话说不能完全模拟用户的请求
当然,上述的设计也存在一些待解决的问题,比如:
- 若将代理部署至应用前端镜像所有请求,再分发至扫描引擎检测,如何防止真实用户数据泄漏和篡改?可能的解决方案是设置例外,对于敏感字段或者请求进行例外处理。
写在最后
Anyway, 新系统的设计无非是汲取前人的智慧加以优化再为后人铺路,解决问题才是考验系统能力的关键!后续我会继续努力改进其不足,让其更加易于使用!
注:如觉得有意思想转载的话,请注明出处,尊重知识产权,从你我开始,谢谢!