本文主要是介绍一下笔者对于甲方安全能力建设的一些经验,心得和零散的思考。需要特别强调的是不同企业的实际情况不尽相同,本文仅供参考,不具普遍意义。
0x01 Red Teaming
近几年随着Red Team建设的话题越来越流行,不管是甲方或者乙方都在极力的发展自己的Red Teaming能力,尤其是各个乙方都推出了自己的Red Team的服务,如:FireEye(
https://www.fireeye.com/content/dam/fireeye-www/services/pdfs/pf/ms/ds-red-team-for-security-operations.pdf),但是最终目的都是为甲方输出检验企业的Detection和Response的能力,找到防御弱点进而优化防御系统和流程。
我们不禁要思考一下,到底什么样的企业才真的需要Red Team?当然,输出安全能力和服务的乙方不在讨论范围内,因为其最终是为了服务和支持甲方。根据我的观察和发现,目前大部分人很容易把Red Team和Penetration Testing弄混或者干脆混为一谈。其实二者有共同点但也有本质上的不同,简单做个比喻就是忍者(隐秘,快速,准确,一击即中)和海盗(强壮,贪婪,可以刚正面,一波高地)的区别,各有侧重和优劣,但侧重点不同,比如,Red Team类似忍者,侧重于精心准备(如:社会工程学等)收集信息进而绕过现有的防御体系(类似于APT)来检验防御和检测能力;而Penetration Testing则如同海盗,侧重于尽可能多地发现应用,系统,网络,设备等的漏洞,并利用其发现更深层或者复杂的漏洞从而来评估风险。所以,答案显而易见,一个企业只有拥有了基本的防御和检测的能力,并需要持续检测和改善这种能力时,Red Team就是很好地选择了。
那么,什么样的Red Team才算合格和有效呢?如前面所说,Red Team如同忍者去做暗杀,既然暗杀那么就需要一个详细的计划,如:目标是什么(暗杀对方头目),手段是什么(前期侦查对方大本营,守卫布局,对方头目的日常习惯和出现的场所,会不会功夫等),如何去执行(选择某个夜黑风高的晚上,众人都准备或者已经睡觉的时候,摸进对方大本营,提前隐藏在对方头目习惯出现的场所,等待其出现,再一刀毙命)。对应到Red Team就是,
1)设置好这次行动目的是模拟偷取公司的客户资料;
2)提前做好侦查看看公司都可能有哪些人会碰到这类数据,有哪些防御检测方式(如:反病毒,入侵检测,流量分析);
3)针对可能接触数据的人员做定向钓鱼攻击或者面对面的社工,安装专门制作的绕杀软的工具,利用常见的社交或者云存储网站来做C2,等待时机控制机器,获取必要的用户凭证,盗取客户资料,销毁痕迹,最终走人。
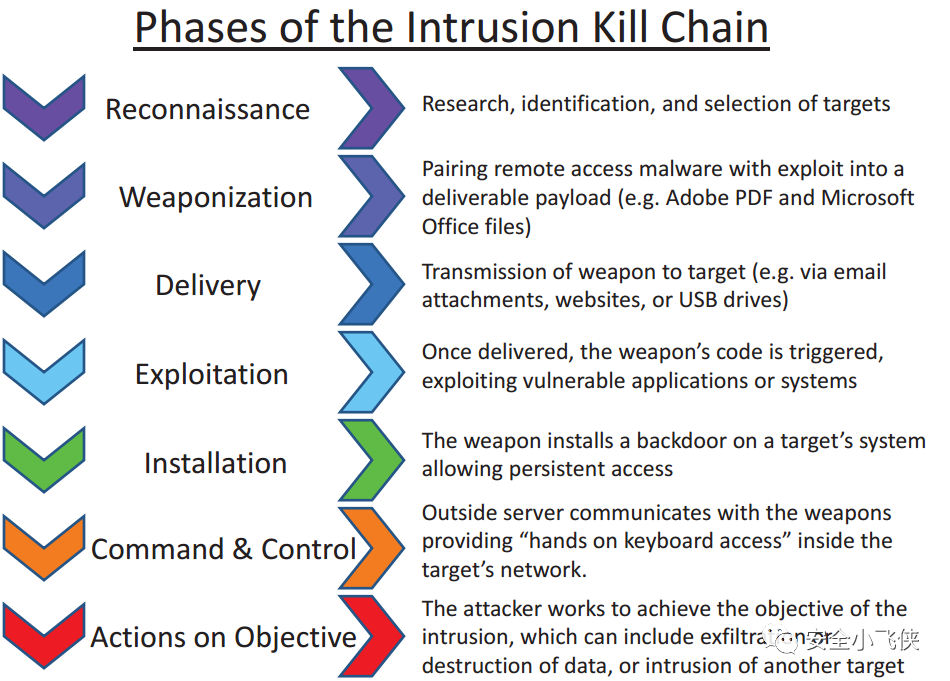
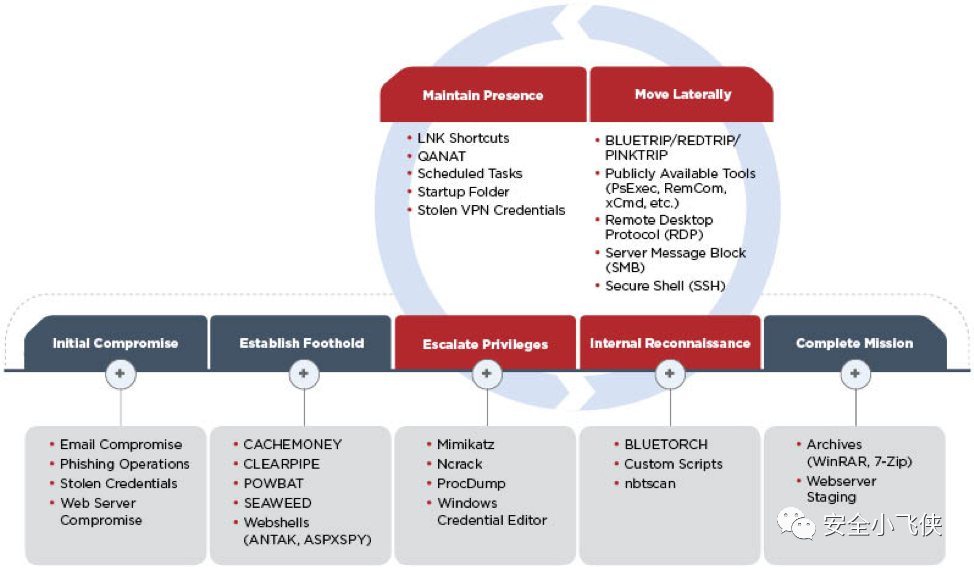
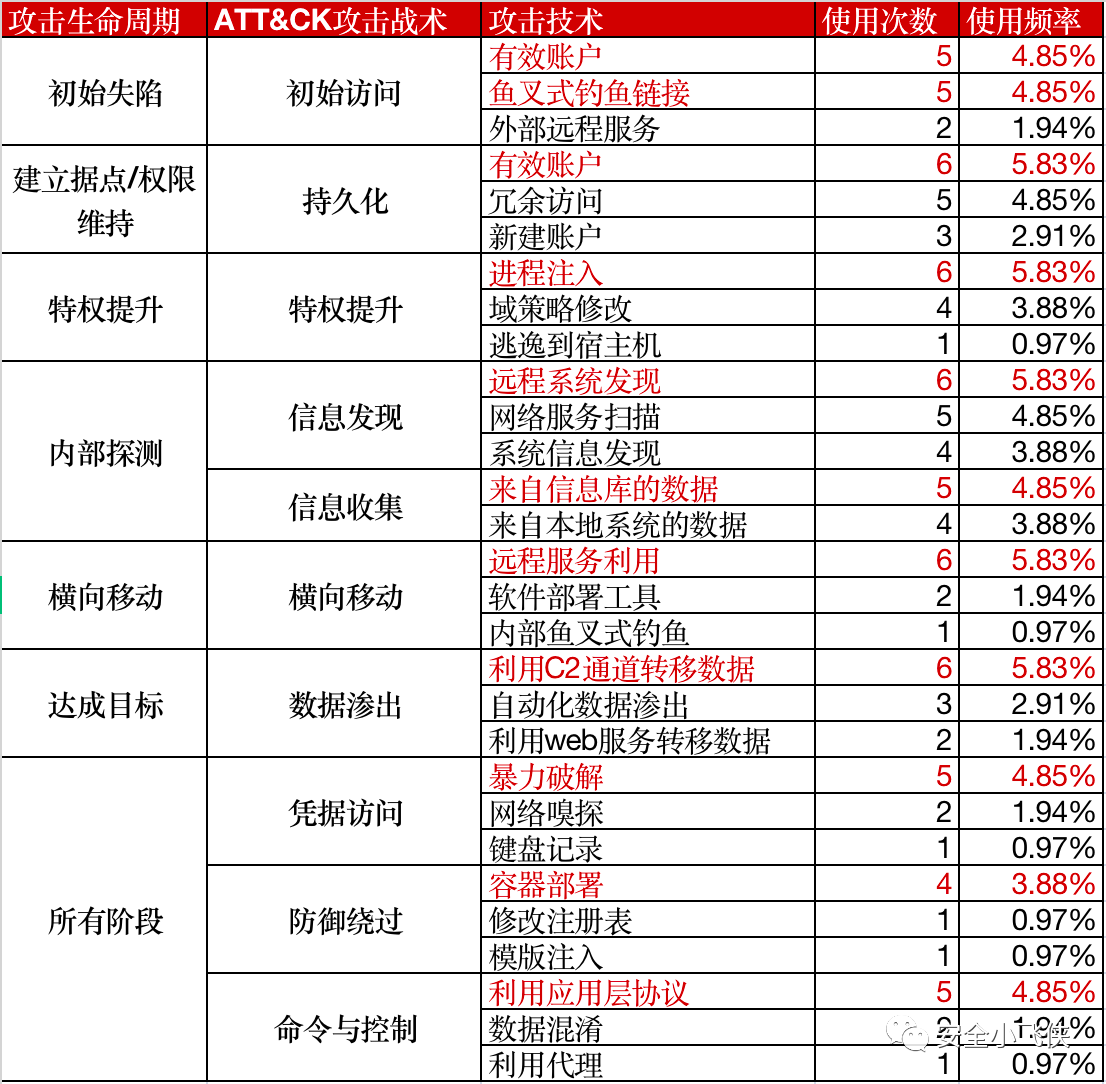
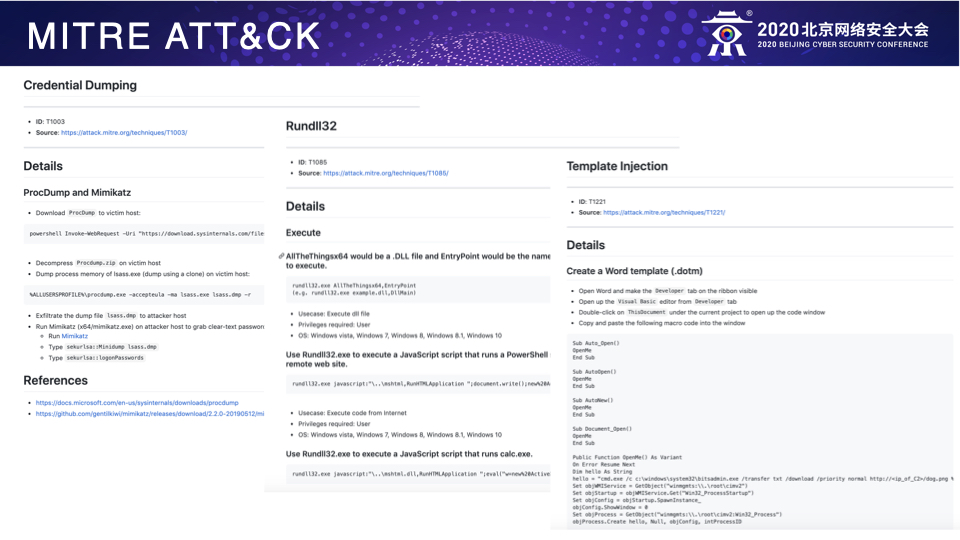
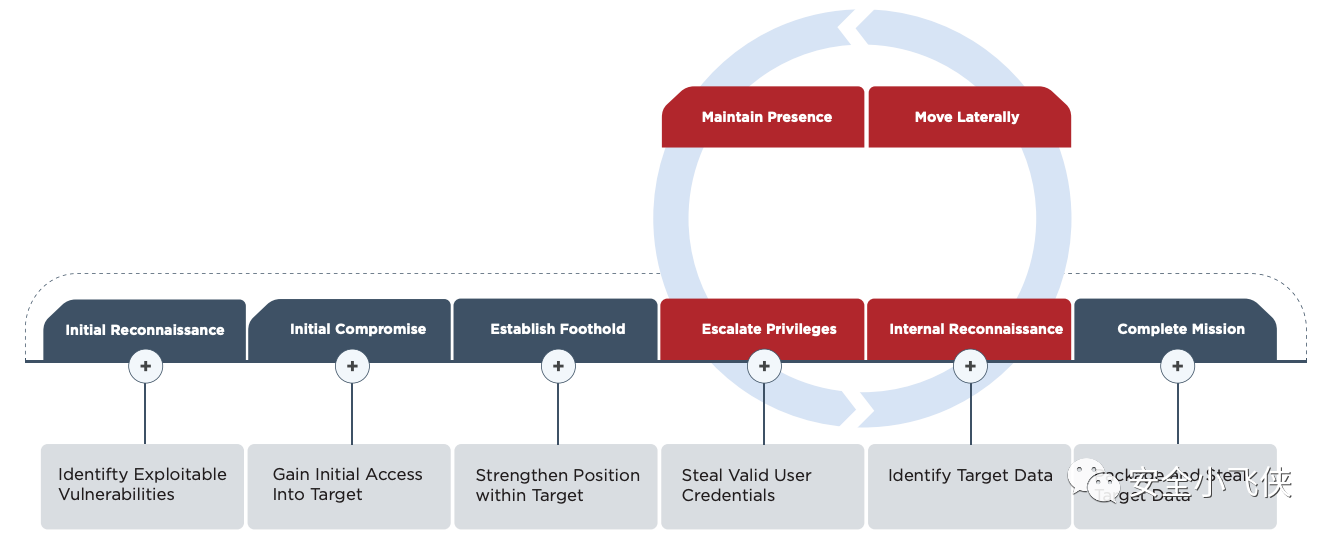
因此,一个合格的Red Team,需要具备模拟攻击者入侵的各种能力,手段以及假想的目的。想要具备这种能力的一个最简单有效的方法,就是从现有的真实世界里发生的APT攻击活动中抽取TTP来模拟真实的threat actors,分类并总结他们曾今采用的手段,方法,技术和工具,然后加以优化和改进,最终结合每个Red Team活动的假想目的来模拟不同APT组织对于公司的入侵,以此来检测已有的防御和响应体系是否有效。
0x02 Blue Teaming
我们在说Blue Team时,通常是指在一个企业里负责入侵检测和应急响应的团队的统称,一般情况下(尤其是规模较大的企业)会至少细分为以下几个团队:
-
Threat Hunting(入侵检测):主要负责根据已知威胁的TTP(如APT活动)和根据常见入侵活动的行为特征(如批量端口扫描,同一系统账户的短时多次尝试登录,office软件进程的可疑子进程的派生等等)来开发入侵检测规则,或者利用机器学习,深度学习等更高级的数据挖掘技术来研究和分析威胁特征;
-
Incident Response(应急响应):主要负责处理和调查企业的安全事件(如:外部应用系统被入侵,内网主机被入侵,以及由Threat Hunting的规则触发的各类入侵报警等)以及从真实的安全事件中来分析和提取自产的IOC以及最新的威胁特征;
-
Vulnerability Management(漏洞管理):主要负责对企业所有资产(包括应用和原代码)的持续漏洞扫描,追踪,修复以及管理;
-
Threat Intelligence(威胁情报):主要负责追踪和分析外部已知APT活动,地下黑市和深网或暗网里的各种威胁情报信息,并加以分类总结成TTP以及IOC提供给其他团队加以利用和深层分析(如前面提到的Threat Hunting,以及Red Team)。
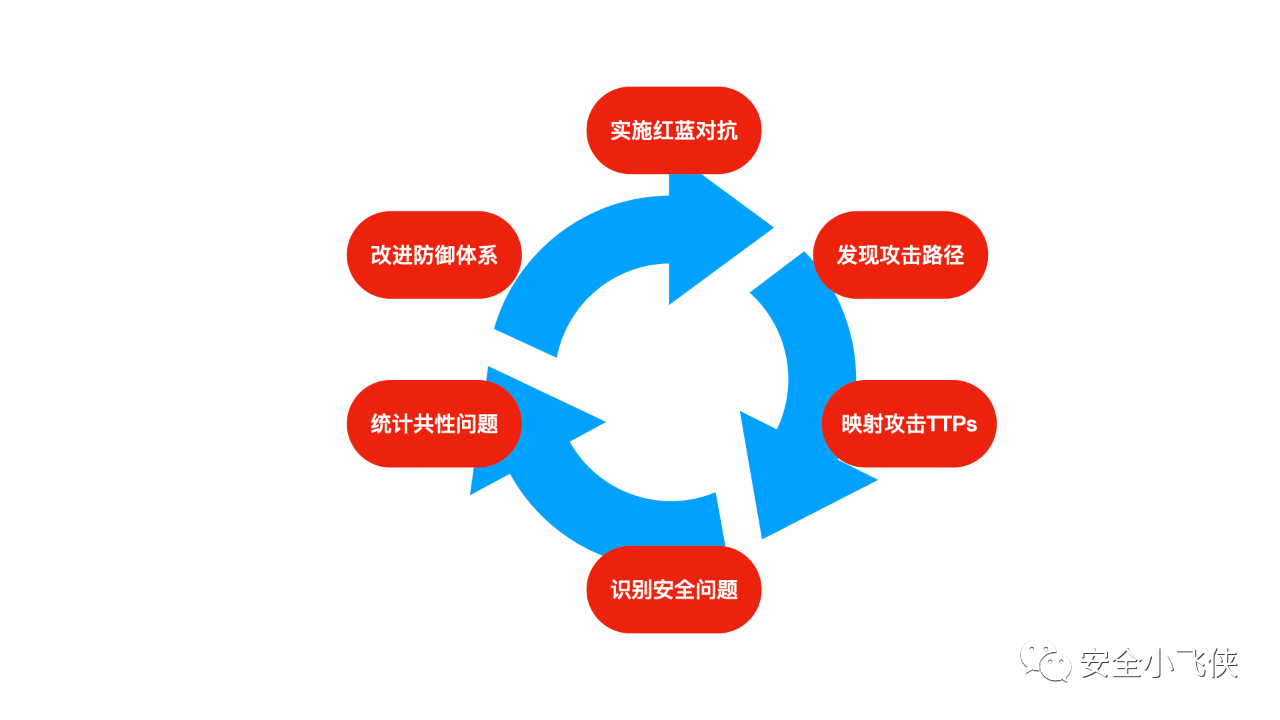
而且这些子团队都不是独立工作的,其之间都是相互配合和支持的。我们可以举个常见的例子来加以解释一下,比如threat hunting可能会通过已知的规则发现了一个可能的入侵行为;接着incident response迅速跟进进行流量、日志或者取证的分析发现了之前未被识别的威胁特征;然后threat hunting基于该特征开发最新的检测规则,threat intelligence以此进行情报梳理和比对并最终发现这是某个最近比较活跃的APT组织的活动,随后搜集相关TTP反馈给threat hunting;最后,vulnerability management团队扫描企业所有可能存在弱点和受影响资产,追踪和修复。
综上可见,Blue Team不是gank选手,而是讲究的团队合作和相互配合的团战协作,合理的利用和集合各个子团队的优势便可以大大提高入侵检测的准确性和应急响应的快速性。
0x03 应急响应
在开始之前,先谈谈我个人理解的应急响应是什么?顾名思义就是对企业发生的安全事件作出快速应对和及时响应从而减少由于安全事件造成的影响。
一般情况下,任何安全事件的应急响应都可以分为以下几个阶段:
1)Assessment(评估):主要是初步梳理安全事件产生的原因和评估潜在影响范围;
2)Containment(控制):这个阶段主要是快速找到止损/减轻方案(或者是临时应对措施)将事件影响尽可能控制在最小范围内;
3)Eradication(消除):这个阶段是要找到安全事件产生的根本原因并提出和实施根治方案;
4)Recovery(恢复):主要是确保所有受影响的系统或者服务完全恢复到安全状态;
5)Review(总结和审查):这是每个应急响应的最后阶段主要是总结和梳理安全事件处理和响应的整个时间线和应对方案,学习和审查安全事件产生的根本原因并生成知识库以便以后遇到同类安全事件可以快速地找到处理和应对的方法。
为了便于大家更好地理解怎么运用以上这些步骤来帮助我们做好应急响应,以下我以一个企业经常会碰到的钓鱼邮件为案例。比如,我们的企业员工上报了一封钓鱼邮件,那么作为应急响应团队应该怎么做?我们都知道钓鱼邮件是入侵者(APT组织)攻击大型企业的最直接有效的方法。当我们的应急响应人员遇到这样的攻击试图时,
第一步,我们要初步分析钓鱼邮件的攻击方法,通常有以下两种。分析了攻击方法,我们就需要评估影响,比如,哪些人收到了该邮件,哪些人可能访问了恶意链接,哪些人下载了恶意文件,哪些人执行了恶意文件,哪些数据可能受到影响等等;
-
Credential Harvesting:设置一个伪造的邮箱或者系统登录界面(如发送一个诱饵链接或者在邮件里嵌入一个html页面)来盗取有效的用户名和密码;
-
Malware:一般包括两种方式,一是通过附件直接发送恶意文件,二是通过发送链接来诱骗用户点击下载恶意文件。
第二步,实施控制措施或者减轻方案,如针对通过链接来偷取用户名和密码或者下载第一阶段的恶意文件的域名我们可以实施DNS sinkhole(详情可以参照:https://en.m.wikipedia.org/wiki/DNS_sinkhole),对于利用附件直接发送恶意文件的情况我们可以通过静态或者动态沙箱(例如cuckoo,virustotal等)来分析恶意文件的行为并抽取IOC(可能是后续阶段C2的域名或者IP,亦或者是执行的子命令)实施DNS sinkhole,防火墙IP黑名单,或者终端防安全防护软件添加行为识别特征或者文件hash黑名单等等措施;
第三步,当恶意行为被有效控制后,我们便需要实施清除活动,如:清除所有收到的恶意邮件,对访问过恶意链接并且可能潜在泄露过用户名和密码的用户进行账号重置,对于下载执行过恶意文件或者访问过后续阶段的域名或者IP的用户电脑进行重装等等;
第四步,这个阶段我们需要确保我们在第三步中的所有清除活动按照预期完成,并且所有用户和系统恢复正常使用;
第五步,当一切恢复正常,我们需要对这次的钓鱼邮件事件做复盘分析,如:为什么我们的邮件安全网关没有检测到和拦截这个钓鱼邮件?为什么我们的员工会点击这些钓鱼邮件?我们的防御和检测的漏洞在哪?下次再发生类似事件我们应该怎么办?等这些问题都找到对应的答案了我们则需要录入应急响应知识库以备后用。
综上,一个有效的应急响应是需要一个相对完整的流程来保证,如此一来便可以保证应急时不慌乱有条理且快速有效。
0x04 内网入侵检测与防御
本章节将依据我个人的一些工作经验和思考分别从平台搭建,工具配置,入侵调查与分析三个方面来聊聊企业的内网入侵检测和防御的建设思路。
一、平台篇
通常来说,一个企业要想做好内网检测和防御,首先要解决的问题就是感知能力,这就好比是人的五官要可以感知到周遭环境的变化,那么反映到安全平台上我们就需要一个统一的日志收集和分析平台。那么需要收集哪些日志呢?是所有的都收集吗?还是有选择性地收集?又如何来确定优先级呢?其实日志的收集切忌盲目全收,否则就会浪费了大量的人力物力财力到头来搜集了一堆日志却不知道如何使用。最好是结合应用场景来制定优先级,循序渐进。举个例子,比如当我们的一个应用场景是检测办公网中的入侵行为,我们需要解决的核心问题其实就是谁在什么时间什么机器上运行了什么进程做了什么操作。分解一下这个问题,首先我们需要有日志能帮我们定位每个内网用户,如:DHCP,DNS,Kerberos Tickets(AD认证),Windows Event Logs,Antivirus等;接着我们想要知道什么时间什么机器上运行了什么,如:主机进程树和网络连接日志(即:Event Tracing for Windows)等;最后我们需要知道做了什么操作(网络行为等),如:网络设备出口流量,Web网关日志(HTTP流量),IDS日志,WiFi日志,邮件网关日志等等。这样,我们就能有针对性地收集我们当下最需要的日志并可以利用这种方法来逐步扩大日志收集的种类。
有了统一的日志收集平台,接下来我们便需要一个持续的威胁检测平台其主要作用就是编写各种检测规则和机器学习模型来对所有收集到的日志进行匹配检查以保证之前的已知威胁不会被忽略。
接着,我们需要一个IOC检测平台,其主要作用是用来对外部情报信息或者内部自产的情报信息进行实时匹配和报警以确保当前所有的已知威胁能被检测出来。
最后,我们还需要一个内部威胁追踪和记录平台,其主要作用是用于流程化和规范化地记录和总结所有以往发生的入侵事件的调查过程和分析结果以便于日后查询和关联分析。
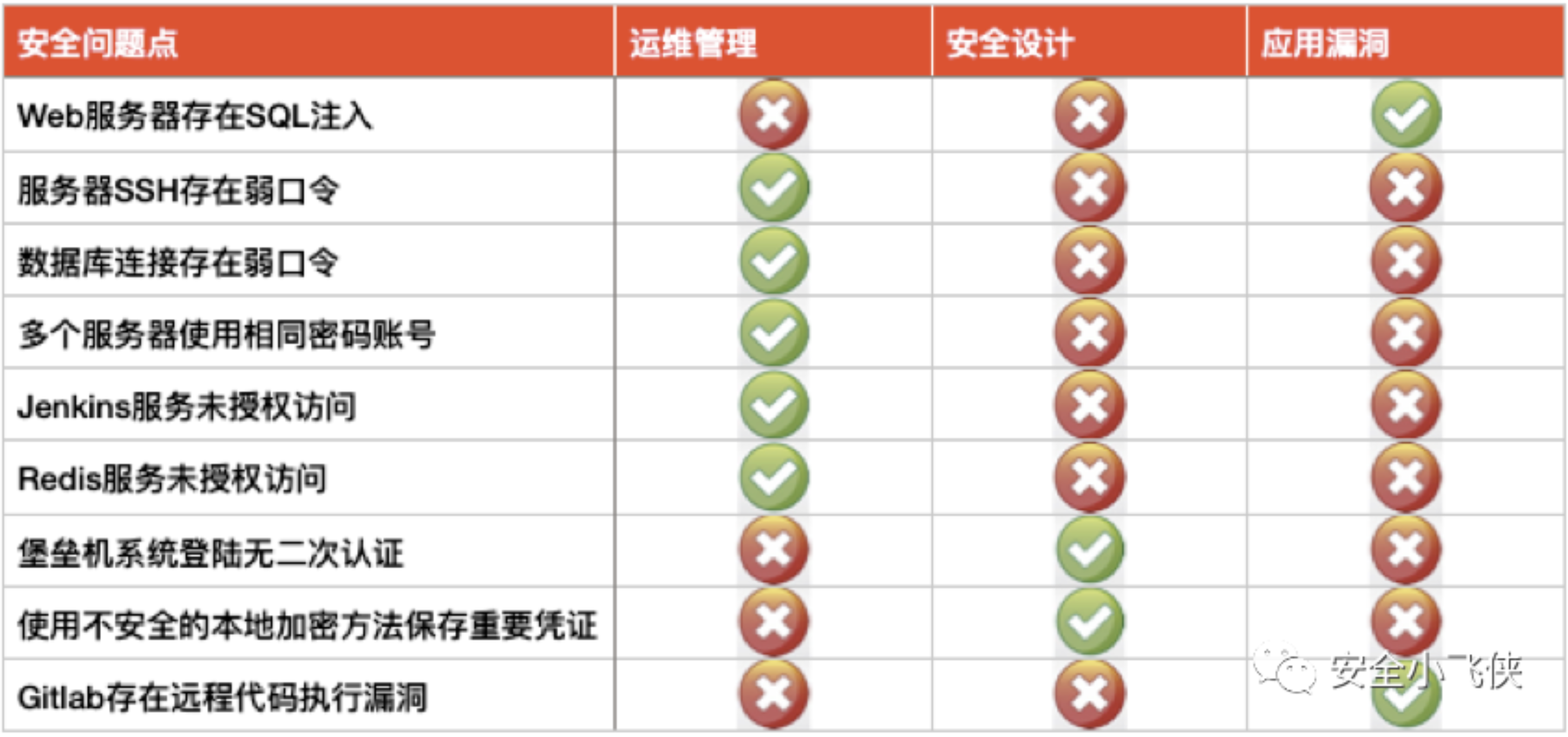
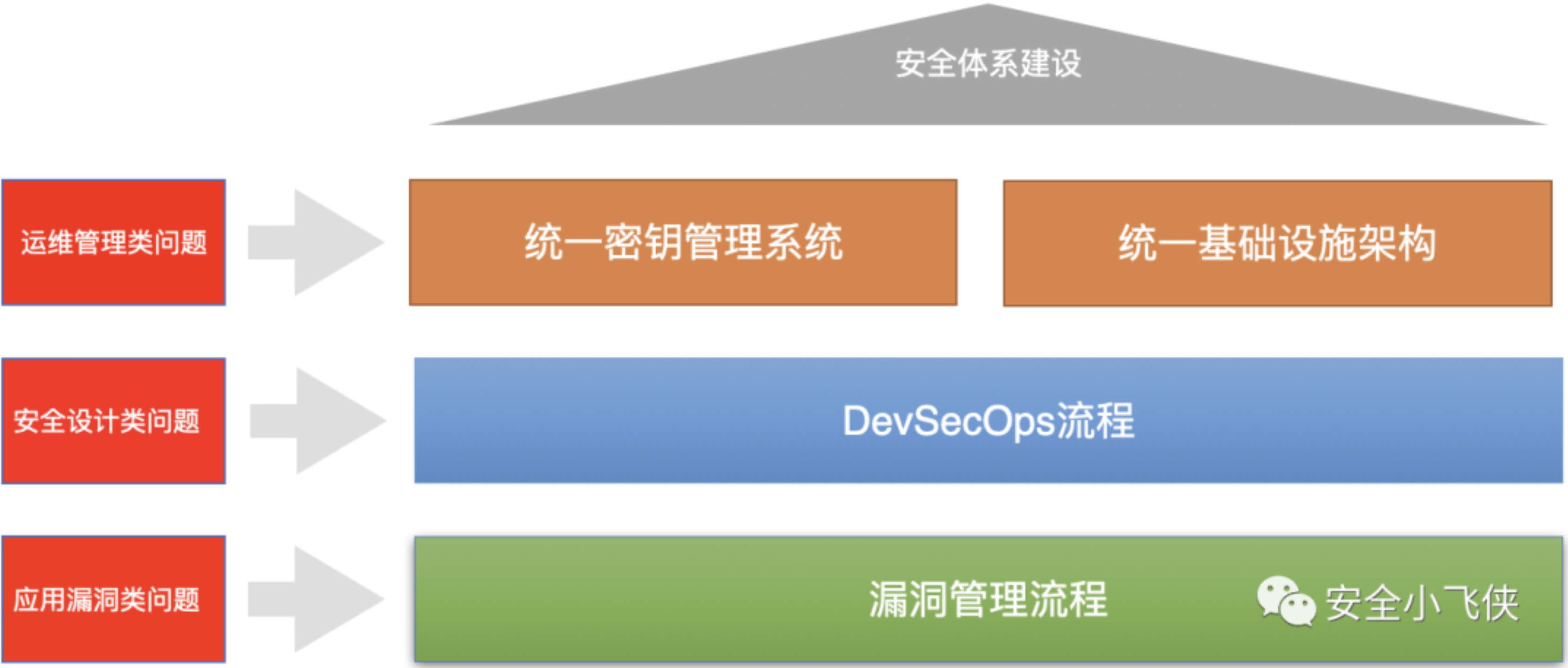
总之,安全平台建设是企业内网入侵检测和防御的基础,只有搭建了这些基础平台,才能谈后续的工具配置和入侵分析与调查。
二、工具篇
在上一篇中我们聊到安全平台建设是企业内网入侵检测和防御的基础,在这个基础之上今天我们来聊聊工具配置。简而言之,就是有了感知能力,需要哪些工具来帮助我们分析和调查入侵,所谓工欲善其事必先利其器。
一般来说,最常见的入侵内网的手法就是钓鱼邮件和社工,而其中以钓鱼邮件最为典型,因此做好钓鱼邮件的防范是最为简单有效的防御内网入侵的方法。我之前曾提到过钓鱼邮件的常见手法,
-
发送链接模拟邮箱或者内部系统登陆界面收集企业员工的账号密码;
-
发送链接诱导员工点击下载恶意的office文档;
-
直接发送恶意的office文档或者PE文件或者恶意程序的压缩包作为附件并诱导员工打开。
针对以上几种手法,我们至少准备以下几类工具来辅助分析。
第一类,域名与IP检测工具:
-
https://centralops.net/co/DomainDossier.aspx?dom_whois=1&net_whois=1&dom_dns=1
-
https://www.threatcrowd.org/
-
https://www.threatminer.org/
-
https://www.virustotal.com/en/
-
https://www.talosintelligence.com/
-
https://login.opendns.com/
-
https://www.alexa.com/siteinfo
-
https://x.threatbook.cn/en
-
https://checkphish.ai/domain/avfisher.win
第二类,URL检测工具:
-
https://urlscan.io/
-
https://sitecheck.sucuri.net/results/pool.cortins.tk
-
https://quttera.com/
-
https://www.virustotal.com/en/
-
https://checkphish.ai/
第三类,TOR节点检测工具:
-
https://www.dan.me.uk/torcheck
-
https://exonerator.torproject.org/
-
https://ipduh.com/ip/tor-exit/
-
https://torstatus.blutmagie.de/
第四类,在线恶意程序或文档检测工具:
-
https://www.virustotal.com/en/
-
https://malwr.com/
-
http://camas.comodo.com/
-
https://x.threatbook.cn/en
-
https://www.reverse.it/
-
http://www.threatexpert.com/submit.aspx
-
https://www.vicheck.ca/
-
https://virusshare.com/
-
https://malshare.com/
-
https://github.com/ytisf/theZoo
第五类,动态恶意程序或文档分析工具:
-
Cuckoo: https://github.com/cuckoosandbox/cuckoo
-
Regshot: https://sourceforge.net/projects/regshot/
-
Process Hacker: http://processhacker.sourceforge.net/
-
Process Monitor: https://technet.microsoft.com/en-us/sysinternals/processmonitor.aspx
-
ProcDOT: https://www.cert.at/downloads/software/procdot_en.html
-
WinDump: https://www.winpcap.org/windump/
-
Graphviz: http://www.graphviz.org/Download..php
-
Capture-BAT: https://www.honeynet.org/node/315 (x86 environment only)
-
Fakenet: https://sourceforge.net/projects/fakenet/
-
Wireshark: https://www.wireshark.org/#download
第六类,邮件检测工具:
第七类,Google搜索,这也是最简单暴力但却十分有效的工具之一。
在分析内网入侵时合理地使用以上这些工具往往会有事半功倍的效果。另外,作为一个入侵分析和响应工程师切忌在没有网络隔离的情况下在办公电脑上直接访问可疑链接或者分析恶意样本文件。
三、分析篇
在前两篇中,我们分别谈到了企业内网入侵检测和防御所需要的安全平台建设和工具配置,有了这些基础我们便来聊聊如何运用这些已有的平台和工具来分析真实的内网入侵事件。
为了更好的说明这个问题,我将仍以最常见的利用钓鱼邮件入侵企业员工电脑并进而入侵内网为例来说明如何分析这类的入侵事件。为了能够检测和分析这类入侵事件,我们需要有能力获得最原始的钓鱼邮件,这就需要我们从至少以下几个途径来获取:
-
企业员工主动提交可疑的钓鱼邮件,这就需要员工具备一定的安全意识(安全意识培训的重要性),以及统一的可疑邮件提交平台(需要开发成本)
-
邮件安全网关,如:Ironport,FireEye Email Security等
-
IOC检测平台,及时检测已知的恶意域名或者IP,可疑的发件人,恶意附件等
当我们拿到了原始的钓鱼邮件,首先需要确保将其转化成EML文本格式(可用工具https://github.com/mvz/msgconvert),接着,我们至少需要从以下几个方面来分析:
1)原始邮件头,包括:From, envelope-from, SPF, client-ip等;
1.1)可以通过dig命令,如:dig -t txt baidu.com,来检查邮件是否被spoof了;
1.2)对比From和envelope-from是否一致,也是一个判断是否为恶意邮件的有效方法.
2)原始邮件正文,包括:域名/IP,URL,附件等;
2.1)域名/IP和URL的分析可以使用工具篇里提到的相应工具来分析,判断是否存在multi-stage C&C;
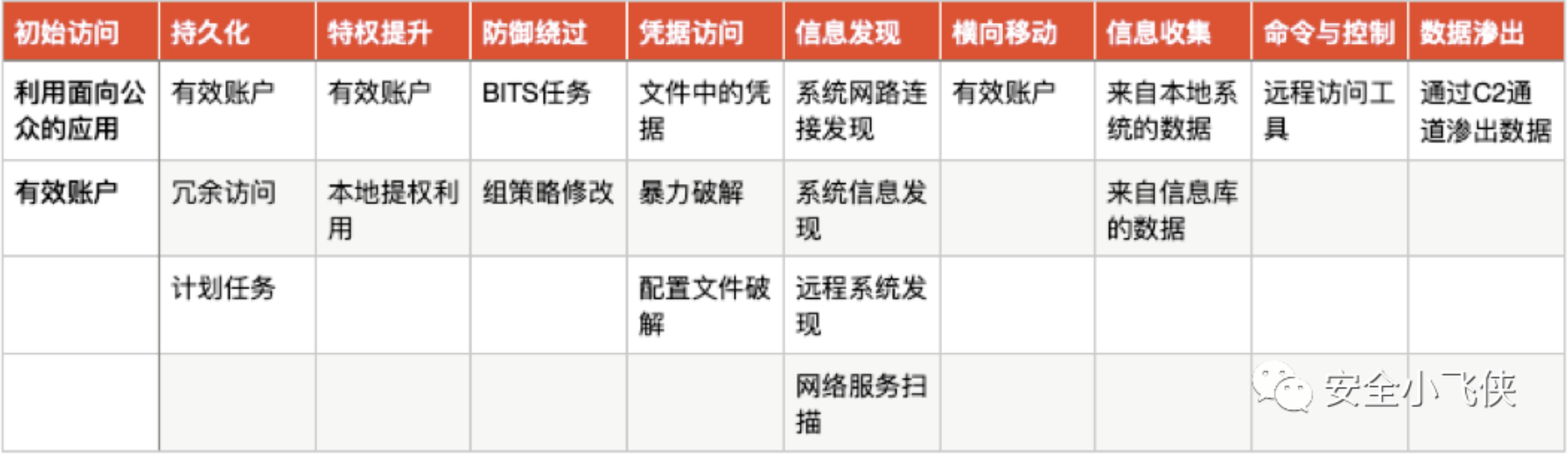
2.2)附件的分析也可以使用工具篇里提到的在线/本地恶意程序分析沙箱或者自行逆向分析,进而了解恶意程序的执行逻辑以及对应的IOC(域名,URL,文件,注册表键值,执行的系统命令等);
2.3)利用日志分析平台,查询恶意域名的DNS或者HTTP(S)流量日志,结合主机EDR(Endpoint Detection and Response)终端日志将DNS请求关联到相应的主机进程,如:ETW for Windows,BCC/eBPF for Linux等;
2.4)查询触发恶意域名的DNS请求的主机进程的整个进程树,分析malware完整的执行链,例如:outlook.exe -> winword.exe -> cmd.exe -> powershell.exe;
2.5)查询所有触发了上述执行链的受感染主机,并重复2.4)的步骤直到没有新的执行链被发现为止.
在分析完了以上这些,我们就可以添加对应的防御和检测措施了,例如:
1)通过应急响应章节中提到的DNS Sinkhole来阻断所有恶意域名的DNS请求;
2)确保终端反病毒程序可以检测并清理每个阶段的恶意文件;
3)添加防火墙规则来阻止内网主机对恶意IP地址的访问;
4)隔离重装已经感染的主机进行;
5)重置受感染内网用户的登录凭证;
6)删除所有企业用户收到的来自同一恶意发送者的邮件;
7)将分析得出的IOC添加到IOC检测平台;
8)依据已发现的Malware执行链添加新的入侵检测规则.
至此,我已简单地介绍了一个相对完整的针对利用钓鱼邮件入侵企业员工电脑并进而入侵内网的入侵事件的分析和防御的方法与流程。















{kind=link}