0x00 前言
本文主要是谈谈笔者对于如何建设体系化的安全运营中心(SOC)的一点经验和思考,观点仅代表个人,仅供参考,不具普遍意义。
0x01 什么是SOC
SOC, 即Security Operations Center,我们一般称之为安全运营中心,主要是负责企业的入侵检测,应急响应,以及安全监控等,通常我们会笼统地概括成两个方面即Blue Team (Defensive Security)和Red Team (Offensive Security),详见《甲方安全建设的一些思路和思考》,这里不再赘述了。
那么什么样的企业需要SOC呢?笔者认为凡是有安全团队的企业都需要这样的一个团队。唯一的区别在于,企业规模的大小和业务的复杂性决定了SOC的职责范围和其运作方式。举个例子,对于规模较大的互联网企业,它的SOC的职责包括但不限于以下几种:
- Incident Response (应急响应)
- Malware Analysis (病毒分析)
- Digital Forensics (电子取证)
- Threat Hunting (入侵检测)
- Threat Intelligence (威胁情报)
- Vulnerability Management (漏洞管理)
- Penetration Testing (渗透测试)
- Red Teaming
而规模较小的企业,则可以按照企业实际的规模和业务需要逐步包含以上的职责范围。
0x02 如何组建SOC
理论基础
在组建SOC之前,我们需要对一些基本安全理论有一定的了解。只有掌握了这些基础理论知识,我们在组建SOC的时候就会比较有针对性和方向性。
应急响应的ACERR处理模型
一般情况下,任何安全事件的应急响应都可以分为以下几个阶段:
- Assessment(评估):主要是初步梳理安全事件的类型,产生的原因和评估潜在影响范围;
- Containment(控制):这个阶段主要是快速找到止损/减轻方案(或者是临时应对措施)将事件影响尽可能控制在最小范围内;
- Eradication(消除):这个阶段是要找到安全事件产生的根本原因并提出和实施根治方案;
- Recovery(恢复):主要是确保所有受影响的系统或者服务完全恢复到安全状态;
- Review(总结和审查):这是每个应急响应的最后阶段主要是总结和梳理安全事件处理和响应的整个时间线和应对方案,学习和审查安全事件产生的根本原因并生成知识库以便以后遇到同类安全事件可以快速地找到处理和应对的方法。
Cyber Kill Chain模型
Cyber Kill Chain模型将攻击者的攻击过程分解为如下七个步骤:
- Reconnaissance(侦查): 入侵者选择目标,对其进行研究,并尝试识别目标网络中的漏洞;
- Weaponization(工具化): 入侵者创建针对一个或多个漏洞定制的远程控制的恶意软件工具,例如病毒或蠕虫;
- Delivery(投送): 入侵者将恶意软件工具投递到目标(例如,通过电子邮件附件,网站或USB驱动器);
- Exploitation(攻击利用): 恶意软件工具的利用触发器,它在目标网络上执行来利用漏洞;
- Installation(安装植入): 恶意软件工具安装入侵者可用的后门;
- Command and Control(命令与控制): 恶意软件使入侵者能够对目标网络进行持久访问和利用;
- Actions on Objectives(目标行动): 入侵者采取行动实现其最终目标,例如数据泄露,数据销毁或加密勒索。
通过以上的模型将攻击者的攻击过程分解,我们就可以找到对应的防御方法:
- Detect(检测):确定攻击者是否在嗅探或者扫描;
- Deny(拒绝):防止信息泄露和未授权访问;
- Disrupt(中断):阻止或更改攻击者的出站流量;
- Degrade(降级):反击命令与控制;
- Deceive(欺骗):干扰命令与控制;
- Contain(控制):网络分段隔离。
MITRE’s ATT&CK矩阵
MITRE’s ATT&CK矩阵,是一个用于分析网络入侵者的战术和技术的知识库,它可以用于了解和分析攻击者所有当前已知的攻击技术和行为,以便于规划安全性改进以及验证防御体系是否正常工作。通俗地说,这其实就类似于对攻击者进行画像,再利用这个入侵分析矩阵来全面了解我们的攻击者从而帮我们来设计和改进我们的防御体系。
系统工具
这部分可以参照以下资源,这里就不再赘述了:
- 《甲方安全建设的一些思路和思考》内网入侵检测与防御章节的平台篇和工具篇
- Awesome Incident Response
- How To Build And Run A SOC for Incident Response – A Collection Of Resources
0x03 SOC如何工作
当我们组建好了SOC,如何才能让其有效的工作呢?下面我将分别从组织架构,职责划分,有效协作几个方面来做简单地的讲解。
组织架构
SOC就像一台机器,而SOC的每个组成部分就是机器的一个个零部件。一个体系化的SOC运营就是把整体的安全运营拆分成一个个独立的子模块,通过各个子模块之间的相互配合和协作,最终有效处理一个复杂的安全事件。从组织架构上,一般会把SOC分解为Defensive Security团队和Offensive Security团队,如下:
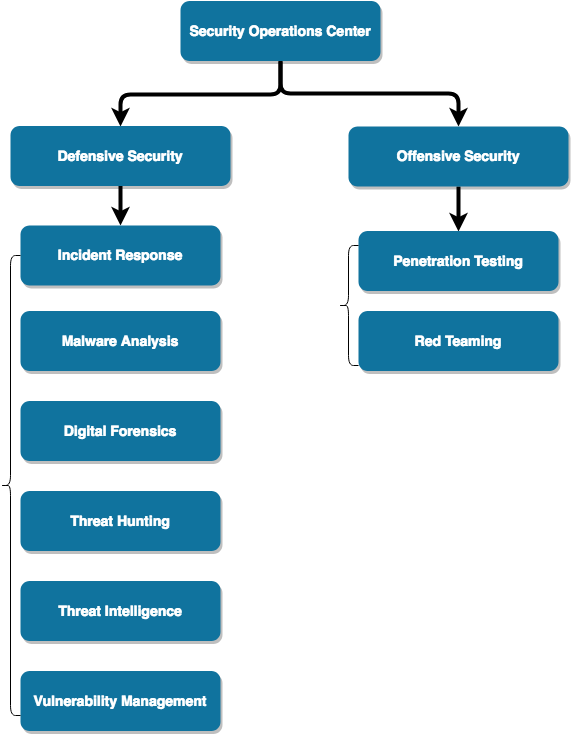
职责划分
SOC组织架构是需要支持不同的工作职责的,我们把这些不同的子模块/团队按照职责的不同划分成以下几类:
Tier 1团队
主要负责直接应对和处理企业内外的各种安全事件,例如:Incident Response,提供7*24小时的应急响应服务。这类团队通常需要具备足够的技术知识面,良好的沟通和协调能力,出色的安全事件分析能力等。
Tier 2团队
主要为Tier 1团队提供技术上的深度支持,例如:Malware Analysis,Digital Forensics,Threat Hunting,Threat Intelligence,以及Vulnerability Management等。这类团队注重的是分析和调查安全事件和问题的根本原因,实施有效的应对措施和防御策略。
Tier 3团队
主要负责从攻击视角来检验当前已有的入侵检测和防御能力,例如:Penetration Testing和Red Teaming等。这类团队侧重于站在入侵者的角度来模拟实际的攻击者对企业资产和信息实施有计划和目的的渗透和入侵,以此来检验Tier 1和Tier 2团队的应对和处置能力,包括:
- 能否检测到?
- 多久能检测到?
- 检测到什么程度?
- 有无实时阻断能力?
- 多久能阻断?
- 等等…
有效协作
当我们已经具备了以上的组织架构和清晰的职责划分,接下来一个问题就是如何让各个团队之间进行有效的协作从而发挥最大的功效来应对各种安全威胁,我将尝试用下面几个典型的案例来简单加以阐述。
被动应急与响应
Incident Response团队收到一个员工上报的钓鱼邮件,进过初步分析发现该钓鱼邮件附带一个HTML文件引诱收件人点击一个外部链接来下载和打开一个Word文档文件,沙箱分析这个文档不包含任何宏来启动PowerShell或者VB脚本等常见利用方法。
首先,Incident Response团队对外部可疑域名执行DNS sinkhole操作。应急响应人员迅速查询邮箱安全网关日志发现多个内部员工收到了来自于该外部可疑发件人的邮件,并立即清除所有邮件服务上的该可疑邮件,同时更新邮件网关的检测和过滤规则。
随后,Malware Analysis团队去深度分析和调查该Word文档。经调查发现该可疑样本利用了一个已公开披露的Office软件的漏洞执行命令从Stage 2域名下载并安装后门来链接C2的IP,调查结果反馈给Incident Response团队。
然后,Incident Response团队根据已获得域名和C2信息分析网络,EDR,DNS,DHCP等日志找到所有执行该Word文档的终端电脑和用户。
Digital Forensics团队跟进对已感染终端进行实时或者线下取证分析获取到更多的IOC和TTP信息,调查结果同样反馈至Threat Hunting和Incident Response团队。
Incident Response团队梳理所有已知信息(包括:域名,IP,文件hash,命令行,注册表等等)添加至IOC检测平台,确保终端防病毒软件可以检测所有已知的后门样本,确保所有已知恶意域名和IP被block,隔离所有已感染主机,重置已感染用户的用户凭证等等。
Vulnerability Management团队扫描所有存在该office软件漏洞的主机并进行补丁推送。
Threat Hunting团队根据所有已知的TTP开发和添加检测规则或者模型用于主动检测。
主动检测与响应
Threat Hunting团队针对某类恶意软件的行为特征开发了一个检测规则或者模型,并触发了一例可疑的告警。
Incident Response团队的安全分析师跟进调查EDR日志发现某终端主机确实存在与该类恶意软件类似的行为特征,并联系Digital Forensics和Malware Analysis团队对感染主机进行实时取证分析和Malware分析,结果显示该恶意软件生成了可以bypass当前终端防病毒软件的后门,并利用了一些当前检测规则未知的方式来与C2通信。同时,分析发现该恶意软件的感染是由于员工安全意识不足插入了不可信的U盘等外部设备引起的。
之后,与被动应急与响应类似,Incident Response团队梳理所有已知信息(包括:域名,IP,文件hash,命令行,注册表等等)添加至IOC检测平台,确保终端防病毒软件可以检测所有已知的后门样本,确保所有已知恶意域名和IP被block,隔离所有已感染主机,重置已感染用户的用户凭证等等。并对引起该问题的员工所在的部门强制进行企业安全意识培训。
最后,Threat Hunting团队根据所有最新调查发现的TTP来更新或者优化当前的检测规则或者模型,以此来形成一个有效的主动检测与响应的安全闭环。
威胁情报分析与利用
Threat Intelligence团队通过情报共享组织掌握到了一条最新的情报,即有黑客在知名黑客论坛售卖能够收集某些特定企业的用户数据的工具,其进行初步地分析和梳理该情报后发现:
- 情报源的可靠性较高,因为其发布于知名黑客论坛,且该黑客以往多次售卖过类似可利用的工具;
- 所在公司确实是该工具宣称的特地目标企业之一;
- 该工具的主要作用是收集目标企业的客户支付信息和账户登录凭证信息;
- 该工具的分发手法主要是社工和web攻击。
Threat Intelligence团队根据情报共享组织提供的已知IOC和OSINT信息整理出了初步的TTP,并反馈给Incident Response团队和Threat Hunting团队。
随后,Incident Response团队跟进分析确定了下一步的调查方向,比如:
- 监控最近一段时间的登录接口以及涉及用户支付流程的页面是否产生了异常流量;
- 检查最近企业的钓鱼邮件的过滤和分析结果,如钓鱼邮件的上升趋势;
- 关注终端的恶意代码检查和趋势分析来尝试找到更多的可能的攻击痕迹;
- 利用一些已知的IOC与内部的日志监控系统做匹配和联动,例如:该黑客的id是已知的,可以尝试做更多的匹配分析来检查恶意代码中是否存在与这个id有关的关键词等。
一旦上述任何调查方向有了新线索,便可以联系Tier 2团队跟进分析和调查,确定更多IOC和TTP,并做相应的应对措施。
最后同上,Threat Hunting团队根据所有已知的TTP开发和添加检测规则或者模型用于主动检测。
Red Teaming实践
Red Teaming团队通过以下的TTP来模拟Threat actors入侵企业从而检验Tier 1和Tier 2团队能否进行有效检测和响应。
目标(Goals)
模拟某个国家级的APT组织来入侵企业从而获得企业的敏感数据
战术(Tactics)
- 鱼叉式钓鱼
- 物理访问
- 社工
- 远控软件的投递与安装
- 确保后门软件不能被虚拟机,debugger或者沙箱分析
-
后门使用加密配置文件,支持高度定制和可配置化,如
- phishing基础架构
- C2基础架构
- 持久化机制
- 加密密钥
- 基于Domain Fronting的C2通信
技术(Techniques)
- PowerShell
- 脚本化与无文件化,如:MsBuild.exe,DotNetToJScript等
- 软件打包bypass防病毒软件
-
保证持久化
- 计划任务
- 注册表/启动目录
- 修改快捷方式
- WMI(Windows Management Instrumentation)事件订阅
- Bypass UAC来实现本地提权
- Pass the Hash/Pass the Ticket来实现横向移动
- Tor proxy配置以及Domain Fronting绕过流量检测
流程(Procedures)
初始感染
利用鱼叉式钓鱼发送钓鱼邮件,将恶意程序放置在信誉度良好的外部站点上,编写精心设计和欺骗性很高的邮件内容来引诱目标用户点击该外部链接打开恶意文档,如word文档,hta文件等。
建立根基
一旦目标用户打开恶意文档,执行PowerShell脚本下载不具备危险性的XML文档并调用MsBuild.exe来执行XML文档中内嵌的恶意代码注入内存来绕过防病毒检测生成一个具备少量功能的downloader,如偷取用户凭证,收集浏览器历史,或者截图等。
权限提升
通过已安装的downloader下发特定的用户凭证盗取工具(如:WCE, Mimikatz, Procdump, Keylogger等)来盗取用户密码或密码hash,同时收集防病毒软件的信息并绕过防病毒来完成权限提升。
内部侦查
通过一些常见的系统命令或者下发定制脚本来探测内网信息,如枚举域信息,组策略对象中的各种用户和用户组配置信息。
横向移动
使用收集到的用户凭证,PtH (Pass the Hash), PTT (Pass the Ticket)利用RDP,PsExec, Mimikatz, RemCom等来完成内网的横向移动。
维持权限
利用计划任务,注册表/启动目录,修改快捷方式等方式来保证持久化。
完成目标
逐步渗透内网的核心机器,偷取企业的核心数据,并利用DNS隧道,Domain Fronting或者加密数据通过HTTPS等更加隐秘的方式外带出去,达成最终目标。
实践活动完成后,Red Teaming团队与Tier 1和Tier 2团队复盘整个模拟入侵过程的时间线,分析和总结没有被检测到的点以及整个入侵防御体系存在的问题,并提出改进方案,以便在下一次的实践中检验改进成果。
0x04 总结
笔者观点,SOC的体系化建设:系统工具是基础,体系结构是重点,有效协同是关键。
0x05 参考
- https://mp.weixin.qq.com/s/0wS4OTuq5yOfdmXSrsmzlg
- http://avfisher.win/archives/984
- https://en.wikipedia.org/wiki/Information_security_operations_center
- https://en.wikipedia.org/wiki/Kill_chain
- https://attack.mitre.org/matrices/enterprise/
- https://osintframework.com/
- https://en.wikipedia.org/wiki/Domain_fronting
- https://www.n00py.io/2018/06/executing-meterpreter-in-memory-on-windows-10-and-bypassing-antivirus/
- https://github.com/tyranid/DotNetToJScript
- https://github.com/meirwah/awesome-incident-response
- https://www.peerlyst.com/posts/how-to-build-and-run-a-soc-for-incident-response-and-enterprise-defensibility-a-collection-of-resources